var url = $"https://api.weixin.qq.com/sns/jscode2session?appid={AppID}&secret={Secret}&js_code={code}&grant_type=authorization_code"; var result = await HttpClientWrapper.GetRspAsync(url);
if (result != null && result.StatusCode == System.Net.HttpStatusCode.OK) { var ret = await result.Content.ReadAsStringAsync(); var ret_obj = Newtonsoft.Json.JsonConvert.DeserializeObject<Hashtable>(ret); var token = await player.client_Mng.token_player_login(ret_obj["openid"] asstring); rsp.rsp(token); }
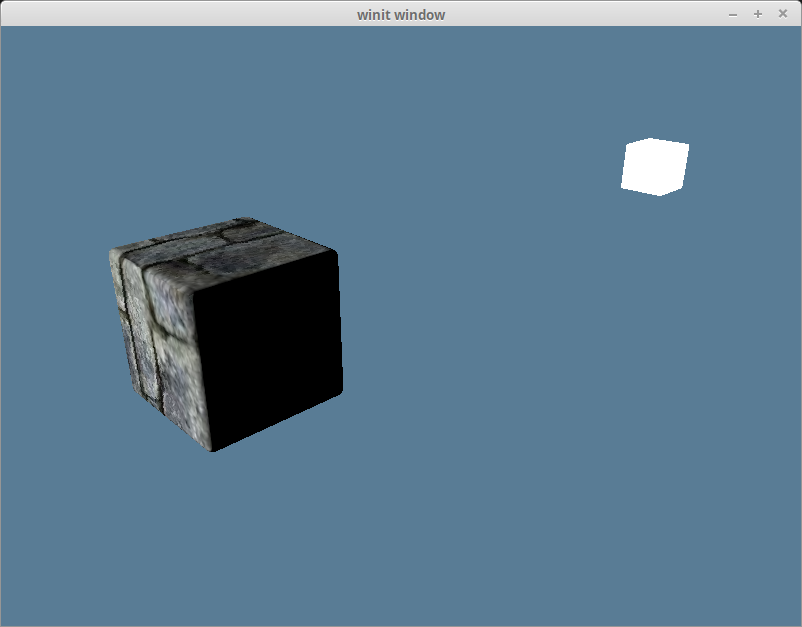
While we can tell that our scene is 3d because of our camera, it still feels very flat. That’s because our model stays the same color regardless of how it’s oriented. If we want to change that we need to add lighting to our scene.
In the real world, a light source emits photons which bounce around until they enter into our eyes. The color we see is the light’s original color minus whatever energy it lost while it was bouncing around.
In the computer graphics world, modeling individual photons would be hilariously computationally expensive. A single 100 Watt light bulb emits about 3.27 x 10^20 photons per second. Just imagine that for the sun! To get around this, we’re gonna use math to cheat.
在计算机图形学领域,对单个光子进行建模在计算上会非常昂贵。一个100瓦的灯泡每秒发射大约3.27 x 10^20个光子。想象一下,为了太阳!为了避开这个问题,我们要用数学来作弊。
Let’s discuss a few options.
让我们讨论几个选项。
Ray/Path Tracing
This is an advanced topic, and we won’t be covering it in depth here. It’s the closest model to the way light really works so I felt I had to mention it. Check out the ray tracing tutorial if you want to learn more.
The Blinn-Phong Model
Ray/path tracing is often too computationally expensive for most realtime applications (though that is starting to change), so a more efficient, if less accurate method based on the Phong reflection model is often used. It splits up the lighting calculation into three (3) parts: ambient lighting, diffuse lighting, and specular lighting. We’re going to be learning the Blinn-Phong model, which cheats a bit at the specular calculation to speed things up.
Before we can get into that though, we need to add a light to our scene.
在我们开始之前,需要在场景中添加灯光。
1 2 3 4 5 6 7 8 9
// main.rs #[repr(C)] #[derive(Debug, Copy, Clone, bytemuck::Pod, bytemuck::Zeroable)] structLightUniform { position: [f32; 3], // Due to uniforms requiring 16 byte (4 float) spacing, we need to use a padding field here _padding: u32, color: [f32; 3], }
Our LightUniform represents a colored point in space. We’re just going to use pure white light, but it’s good to allow different colors of light.
Let’s also update the lights position in the update() method, so we can see what our objects look like from different angles.
我们还将更新update()方法中的灯光位置,以便从不同角度查看对象的外观。
1 2 3 4 5 6
// Update the light let old_position: cgmath::Vector3<_> = self.light_uniform.position.into(); self.light_uniform.position = cgmath::Quaternion::from_axis_angle((0.0, 1.0, 0.0).into(), cgmath::Deg(1.0)) * old_position; self.queue.write_buffer(&self.light_buffer, 0, bytemuck::cast_slice(&[self.light_uniform]));
This will have the light rotate around the origin one degree every frame.
这将使灯光每帧围绕原点旋转一度。
Seeing the light
For debugging purposes, it would be nice if we could see where the light is to make sure that the scene looks correct. We could adapt our existing render pipeline to draw the light, but it will likely get in the way. Instead we are going to extract our render pipeline creation code into a new function called create_render_pipeline().
I chose to create a seperate layout for the light_render_pipeline, as it doesn’t need all the resources that the regular render_pipeline needs (main just the textures).
Now we could manually implement the draw code for the light in render(), but to keep with the pattern we developed, let’s create a new trait called DrawLight.
With all that we’ll end up with something like this.
有了这些,我们最终会得到这样的结果。
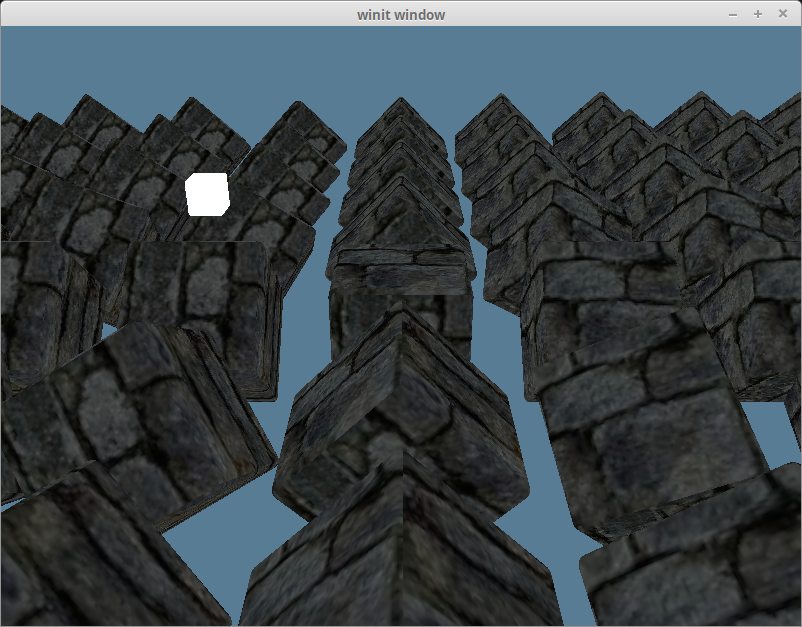
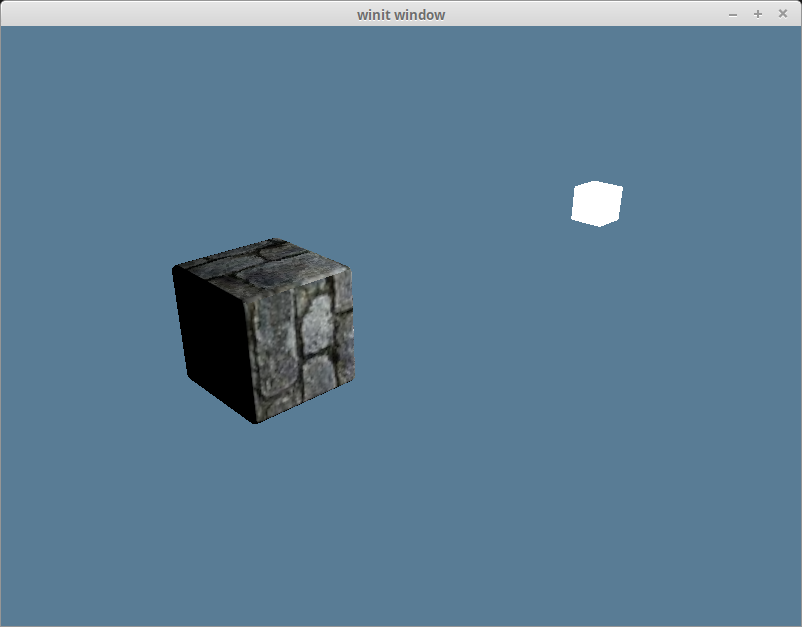
Ambient Lighting
Light has a tendency to bounce around before entering our eyes. That’s why you can see in areas that are in shadow. Actually modeling this interaction is computationally expensive, so we cheat. We define an ambient lighting value that stands in for the light bouncing of other parts of the scene to light our objects.
The ambient part is based on the light color as well as the object color. We’ve already added our light_bind_group, so we just need to use it in our shader. In shader.wgsl, add the following below the texture uniforms.
Then we need to update our main shader code to calculate and use the ambient color value.
然后我们需要更新我们的主着色器代码来计算和使用环境光颜色值。
1 2 3 4 5 6 7 8 9 10 11 12
[[stage(fragment)]] fnmain(in: VertexOutput) -> [[location(0)]] vec4<f32> { let object_color: vec4<f32> = textureSample(t_diffuse, s_diffuse, in.tex_coords); // We don't need (or want) much ambient light, so 0.1 is fine let ambient_strength = 0.1; let ambient_color = light.color * ambient_strength;
let result = ambient_color * object_color.xyz;
return vec4<f32>(result, object_color.a); }
With that we should get something like the this.
这样我们就可以得到类似这样的东西。
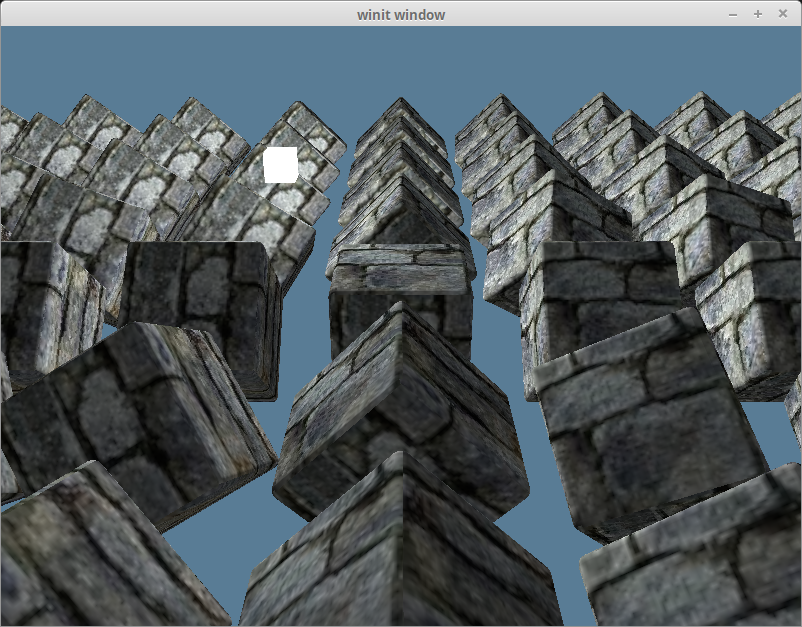
Diffuse Lighting
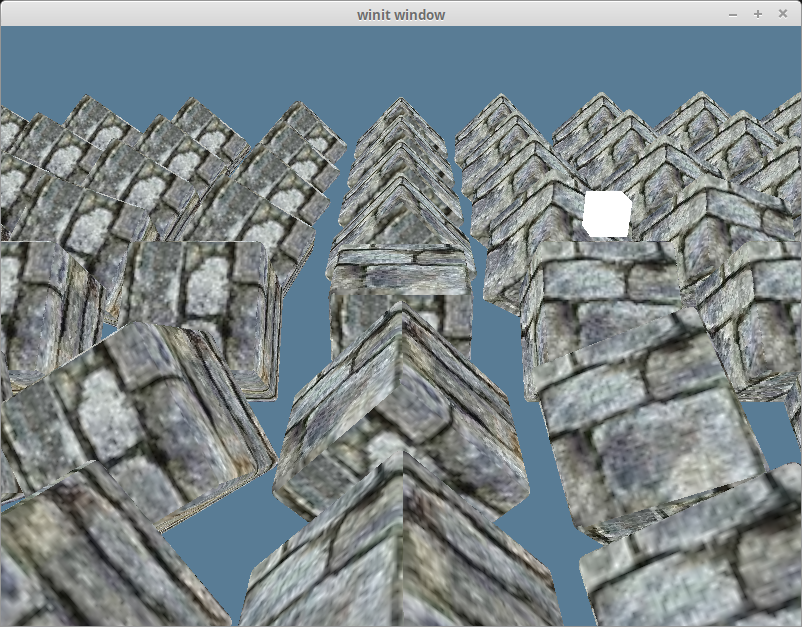
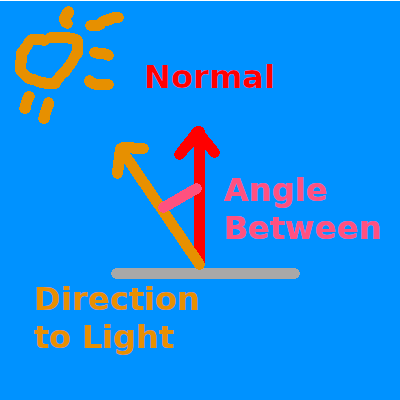
Remember the normal vectors that were included with our model? We’re finally going to use them. Normals represent the direction a surface is facing. By comparing the normal of a fragment with a vector pointing to a light source, we get a value of how light/dark that fragment should be. We compare the vector using the dot product to get the cosine of the angle between them.
If the dot product of the normal and light vector is 1.0, that means that the current fragment is directly inline with the light source and will receive the lights full intensity. A value of 0.0 or lower means that the surface is perpendicular or facing away from the light, and therefore will be dark.
With that we can do the actual calculation. Below the ambient_color calculation, but above result, add the following.
这样我们就可以进行实际计算了。在ambient_color计算下方,但在结果上方,添加以下内容。
1 2 3 4
let light_dir = normalize(light.position - in.world_position);
let diffuse_strength = max(dot(in.world_normal, light_dir), 0.0); let diffuse_color = light.color * diffuse_strength;
Now we can include the diffuse_color in the result.
现在我们可以在结果中包含漫反射颜色。
1
let result = (ambient_color + diffuse_color) * object_color.xyz;
With that we get something like this.
这样我们就得到了这样的东西。
The normal matrix
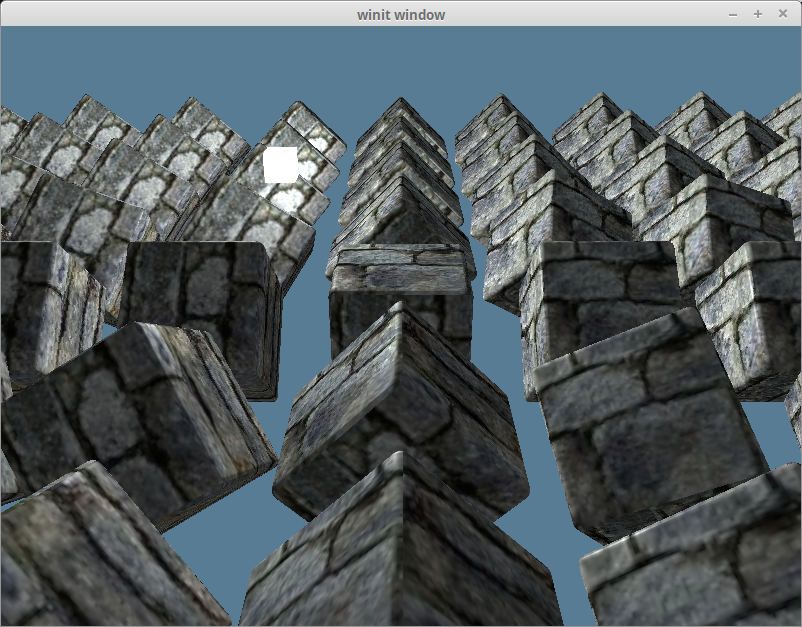
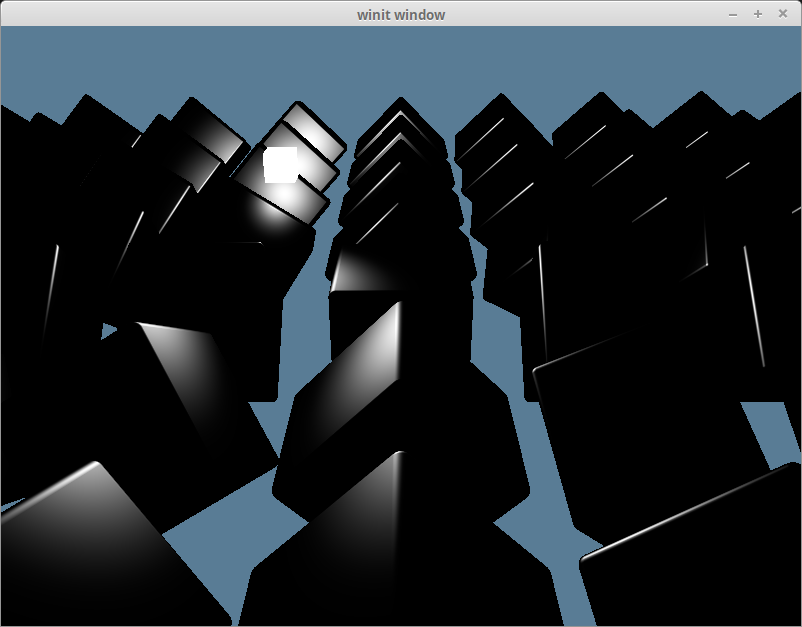
Remember when I said passing the vertex normal directly to the fragment shader was wrong? Let’s explore that by removing all the cubes from the scene except one that will be rotated 180 degrees on the y-axis.
// In the loop we create the instances in let rotation = cgmath::Quaternion::from_axis_angle((0.0, 1.0, 0.0).into(), cgmath::Deg(180.0));
We’ll also remove the ambient_color from our lighting result.
我们还将从照明结果中删除环境光颜色。
1
let result = (diffuse_color) * object_color.xyz;
That should give us something that looks like this.
这应该给我们一些如下图所示的东西。
This is clearly wrong as the light is illuminating the wrong side of the cube. This is because we aren’t rotating our normals with our object, so no matter what direction the object faces, the normals will always face the same way.
We need to use the model matrix to transform the normals to be in the right direction. We only want the rotation data though. A normal represents a direction, and should be a unit vector throughout the calculation. We can get our normals into the right direction using what is called a normal matrix.
We could compute the normal matrix in the vertex shader, but that would involve inverting the model_matrix, and WGSL doesn’t actually have an inverse function. We would have to code our own. On top of that computing the inverse of a matrix is actually really expensive, especially doing that compututation for every vertex.
Instead we’re going to create add a normal matrix field to InstanceRaw. Instead of inverting the model matrix, we’ll just using the the instances rotation to create a Matrix3.
impl model::Vertex for InstanceRaw { fndesc<'a>() -> wgpu::VertexBufferLayout<'a> { use std::mem; wgpu::VertexBufferLayout { array_stride: mem::size_of::<InstanceRaw>() as wgpu::BufferAddress, // We need to switch from using a step mode of Vertex to Instance // This means that our shaders will only change to use the next // instance when the shader starts processing a new instance step_mode: wgpu::VertexStepMode::Instance, attributes: &[ wgpu::VertexAttribute { offset: 0, // While our vertex shader only uses locations 0, and 1 now, in later tutorials we'll // be using 2, 3, and 4, for Vertex. We'll start at slot 5 not conflict with them later shader_location: 5, format: wgpu::VertexFormat::Float32x4, }, // A mat4 takes up 4 vertex slots as it is technically 4 vec4s. We need to define a slot // for each vec4. We don't have to do this in code though. wgpu::VertexAttribute { offset: mem::size_of::<[f32; 4]>() as wgpu::BufferAddress, shader_location: 6, format: wgpu::VertexFormat::Float32x4, }, wgpu::VertexAttribute { offset: mem::size_of::<[f32; 8]>() as wgpu::BufferAddress, shader_location: 7, format: wgpu::VertexFormat::Float32x4, }, wgpu::VertexAttribute { offset: mem::size_of::<[f32; 12]>() as wgpu::BufferAddress, shader_location: 8, format: wgpu::VertexFormat::Float32x4, }, // NEW! wgpu::VertexAttribute { offset: mem::size_of::<[f32; 16]>() as wgpu::BufferAddress, shader_location: 9, format: wgpu::VertexFormat::Float32x3, }, wgpu::VertexAttribute { offset: mem::size_of::<[f32; 19]>() as wgpu::BufferAddress, shader_location: 10, format: wgpu::VertexFormat::Float32x3, }, wgpu::VertexAttribute { offset: mem::size_of::<[f32; 22]>() as wgpu::BufferAddress, shader_location: 11, format: wgpu::VertexFormat::Float32x3, }, ], } } }
We need to modify Instance to create the normal matrix.
I’m currently doing things in world space. Doing things in view-space also known as eye-space, is more standard as objects can have lighting issues when they are further away from the origin. If we wanted to use view-space, we would have include the rotation due to the view matrix as well. We’d also have to transform our light’s position using something like view_matrix * model_matrix * light_position to keep the calculation from getting messed up when the camera moves.
There are advantages to using view space. The main one is when you have massive worlds doing lighting and other calculations in model spacing can cause issues as floating point precision degrades when numbers get really large. View space keeps the camera at the origin meaning all calculations will be using smaller numbers. The actual lighting math ends up the same, but it does require a bit more setup.
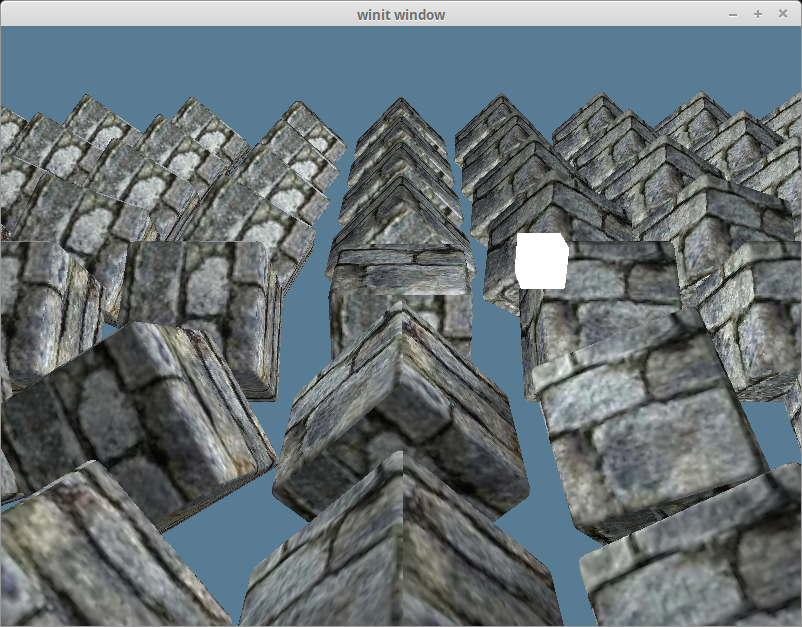
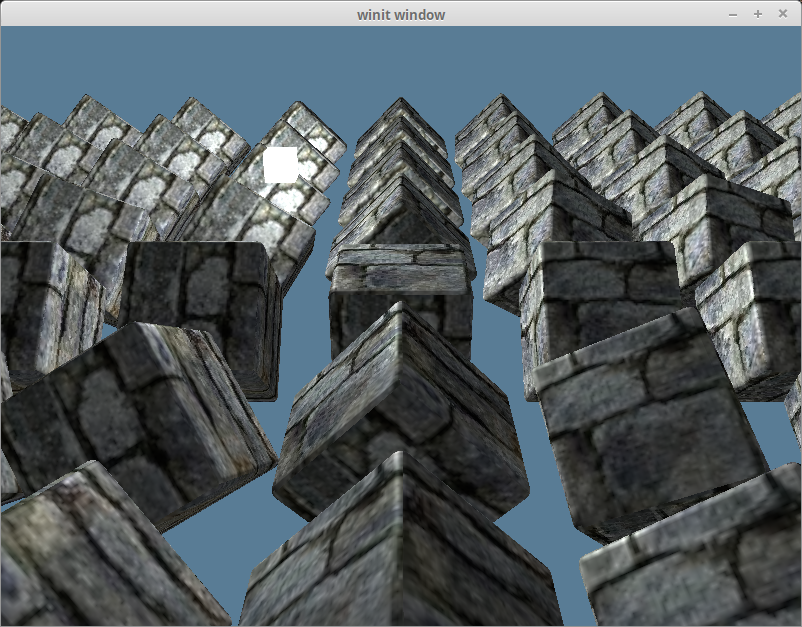
Bringing back our other objects, and adding the ambient lighting gives us this.
带回其他对象,并添加环境照明,我们就可以做到这一点。
Specular Lighting
Specular lighting describes the highlights that appear on objects when viewed from certain angles. If you’ve ever looked at a car, it’s the super bright parts. Basically, some of the light can reflect of the surface like a mirror. The location of the hightlight shifts depending on what angle you view it at.
Because this is relative to the view angle, we are going to need to pass in the camera’s position both into the fragment shader and into the vertex shader.
We’re going to get the direction from the fragment’s position to the camera, and use that with the normal to calculate the reflect_dir.
我们将得到从碎片的位置到摄像机的方向,并将其与法线一起计算反射方向。
1 2 3
// In the fragment shader... let view_dir = normalize(camera.view_pos.xyz - in.world_position); let reflect_dir = reflect(-light_dir, in.world_normal);
Then we use the dot product to calculate the specular_strength and use that to compute the specular_color.
然后我们使用点积来计算镜面反射强度,并使用它来计算镜面反射颜色。
1 2
let specular_strength = pow(max(dot(view_dir, reflect_dir), 0.0), 32.0); let specular_color = specular_strength * light.color;
Finally we add that to the result.
最后,我们将其添加到结果中。
1
let result = (ambient_color + diffuse_color + specular_color) * object_color.xyz;
With that you should have something like this.
这样你就应该有这样的东西。
如果我们只看镜面反射的颜色会如下所示。
The half direction
Up to this point we’ve actually only implemented the Phong part of Blinn-Phong. The Phong reflection model works well, but it can break down under certain circumstances. The Blinn part of Blinn-Phong comes from the realization that if you add the view_dir, and light_dir together, normalize the result and use the dot product of that and the normal, you get roughly the same results without the issues that using reflect_dir had.
Models that should be in the back are getting rendered ahead of ones that should be in the front. This is caused by the draw order. By default, pixel data from a new object will replace old pixel data.
There are two ways to solve this: sort the data from back to front, use what’s known as a depth buffer.
有两种方法可以解决这个问题:从后到前对数据进行排序,使用深度缓冲区。
Sorting from back to front
This is the go to method for 2d rendering as it’s pretty easier to know what’s supposed to go in front of what. You can just use the z order. In 3d rendering it gets a little more tricky because the order of the objects changes based on the camera angle.
A simple way of doing this is to sort all the objects by their distance to the cameras position. There are flaws with this method though as when a large object is behind a small object, parts of the large object that should be in front of the small object will be rendered behind. We’ll also run into issues with objects that overlap themselves.
If want to do this properly we need to have pixel level precision. That’s where a depth buffer comes in.
如果要正确地做到这一点,我们需要有像素级的精度。这就是深度缓冲区的作用。
A pixels depth
A depth buffer is a black and white texture that stores the z-coordinate of rendered pixels. Wgpu can use this when drawing new pixels to determine whether to replace the data or keep it. This technique is called depth testing. This will fix our draw order problem without needing us to sort our objects!
We need the DEPTH_FORMAT for when we create the depth stage of the render_pipeline and creating the depth texture itself.
Our depth texture needs to be the same size as our screen if we want things to render correctly. We can use our sc_desc to make sure that our depth texture is the same size as our swap chain images.
Since we are rendering to this texture, we need to add the RENDER_ATTACHMENT flag to it.
We technically don’t need a sampler for a depth texture, but our Texture struct requires it, and we need one if we ever want to sample it.
If we do decide to render our depth texture, we need to use CompareFunction::LessEqual. This is due to how the samplerShadow and sampler2DShadow() interacts with the texture() function in GLSL.
The depth_compare function tells us when to discard a new pixel. Using LESS means pixels will be drawn front to back. Here are all the values you can use.
There’s another type of buffer called a stencil buffer. It’s common practice to store the stencil buffer and depth buffer in the same texture. This fields control values for stencil testing. Since we aren’t using a stencil buffer, we’ll use default values. We’ll cover stencil buffers later.
Make sure you update the depth_texture after you update sc_desc. If you don’t, your program will crash as the depth_texture will be a different size than the swap_chain texture.
The last change we need to make is in the render() function. We’ve created the depth_texture, but we’re not currently using it. We use it by attaching it to the depth_stencil_attachment of a render pass.
And that’s all we have to do! No shader code needed! If you run the application, the depth issues will be fixed.
这就是我们要做的!不需要着色器代码!如果运行应用程序,深度问题将得到修复。
Challenge
Since the depth buffer is a texture, we can sample it in the shader. Because it’s a depth texture, we’ll have to use the samplerShadow uniform type and the sampler2DShadow function instead of sampler, and sampler2D respectively. Create a bind group for the depth texture (or reuse an existing one), and render it to the screen.
Instancing allows us to draw the same object multiple times with different properties (position, orientation, size, color, etc.). There are multiple ways of doing instancing. One way would be to modify the uniform buffer to include these properties and then update it before we draw each instance of our object.
We don’t want to use this method for performance reasons. Updating the uniform buffer for each instance would require multiple buffer copies each frame. On top of that, our method to update the uniform buffer currently requires use to create a new buffer to store the updated data. That’s a lot of time wasted between draw calls.
If we look at the parameters for the draw_indexed function in the wgpu docs, we can see a solution to our problem.
如果我们查看wgpu文档中draw_indexed函数的参数,我们可以看到问题的解决方案。
1 2 3 4 5 6
pubfndraw_indexed( &mutself, indices: Range<u32>, base_vertex: i32, instances: Range<u32> // <-- This right here )
The instances parameter takes a Range. This parameter tells the GPU how many copies, or instances, of our model we want to draw. Currently we are specifying 0..1, which instructs the GPU to draw our model once, and then stop. If we used 0..5, our code would draw 5 instances.
The fact that instances is a Range may seem weird as using 1..2 for instances would still draw 1 instance of our object. Seems like it would be simpler to just use a u32 right? The reason it’s a range is because sometimes we don’t want to draw all of our objects. Sometimes we want to draw a selection of them, because others are not in frame, or we are debugging and want to look at a particular set of instances.
instances是一个Range的事实可能看起来很奇怪,因为使用1..2 for instances仍然会绘制对象的一个实例。看起来使用u32会更简单,对吗?它是一个Range的原因是因为有时我们不想绘制所有的对象。有时,我们希望选择它们,因为其他的不在视野中,或者我们正在调试并希望查看一组特定的实例。
Ok, now we know how to draw multiple instances of an object, how do we tell wgpu what particular instance to draw? We are going to use something known as an instance buffer.
A Quaternion is a mathematical structure often used to represent rotation. The math behind them is beyond me (it involves imaginary numbers and 4D space) so I won’t be covering them here. If you really want to dive into them here’s a Wolfram Alpha article.
Using these values directly in the shader would be a pain as quaternions don’t have a WGSL analog. I don’t feel like writing the math in the shader, so we’ll convert the Instance data into a matrix and store it into a struct called InstanceRaw.
This is the data that will go into the wgpu::Buffer. We keep these separate so that we can update the Instance as much as we want without needing to mess with matrices. We only need to update the raw data before we draw.
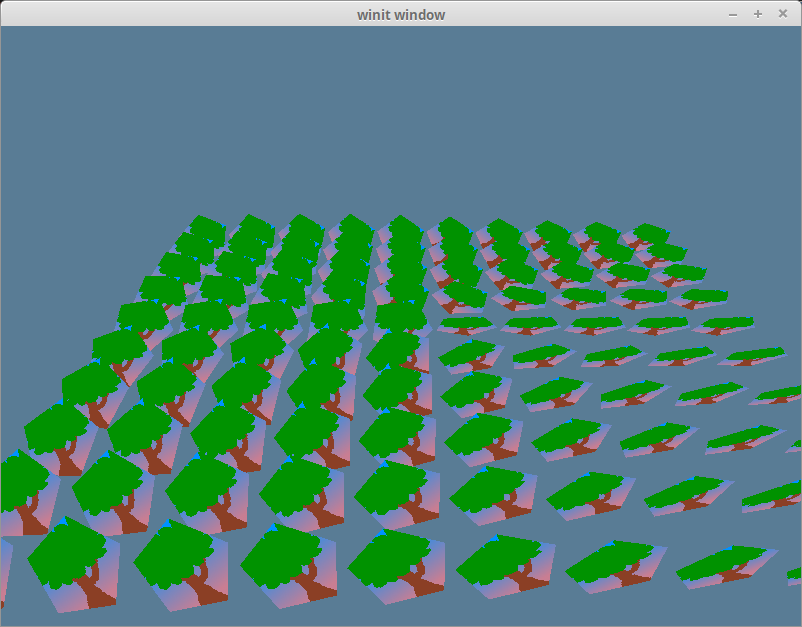
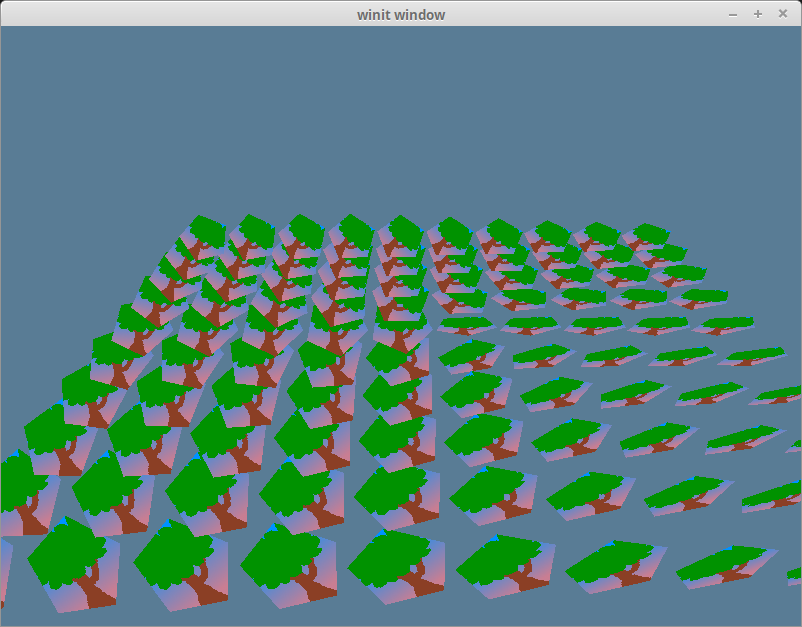
We’ll create the instances in new(). We’ll use some constants to simplify things. We’ll display our instances in 10 rows of 10, and they’ll be spaced evenly apart.
impl State { asyncfnnew(window: &Window) -> Self { // ... let instances = (0..NUM_INSTANCES_PER_ROW).flat_map(|z| { (0..NUM_INSTANCES_PER_ROW).map(move |x| { let position = cgmath::Vector3 { x: x asf32, y: 0.0, z: z asf32 } - INSTANCE_DISPLACEMENT;
let rotation = if position.is_zero() { // this is needed so an object at (0, 0, 0) won't get scaled to zero // as Quaternions can effect scale if they're not created correctly cgmath::Quaternion::from_axis_angle(cgmath::Vector3::unit_z(), cgmath::Deg(0.0)) } else { cgmath::Quaternion::from_axis_angle(position.normalize(), cgmath::Deg(45.0)) };
impl InstanceRaw { fndesc<'a>() -> wgpu::VertexBufferLayout<'a> { use std::mem; wgpu::VertexBufferLayout { array_stride: mem::size_of::<InstanceRaw>() as wgpu::BufferAddress, // We need to switch from using a step mode of Vertex to Instance // This means that our shaders will only change to use the next // instance when the shader starts processing a new instance step_mode: wgpu::InputStepMode::Instance, attributes: &[ wgpu::VertexAttribute { offset: 0, // While our vertex shader only uses locations 0, and 1 now, in later tutorials we'll // be using 2, 3, and 4, for Vertex. We'll start at slot 5 not conflict with them later shader_location: 5, format: wgpu::VertexFormat::Float32x4, }, // A mat4 takes up 4 vertex slots as it is technically 4 vec4s. We need to define a slot // for each vec4. We'll have to reassemble the mat4 in // the shader. wgpu::VertexAttribute { offset: mem::size_of::<[f32; 4]>() as wgpu::BufferAddress, shader_location: 6, format: wgpu::VertexFormat::Float32x4, }, wgpu::VertexAttribute { offset: mem::size_of::<[f32; 8]>() as wgpu::BufferAddress, shader_location: 7, format: wgpu::VertexFormat::Float32x4, }, wgpu::VertexAttribute { offset: mem::size_of::<[f32; 12]>() as wgpu::BufferAddress, shader_location: 8, format: wgpu::VertexFormat::Float32x4, }, ], } } }
We need to add this descriptor to the render pipeline so that we can use it when we render.
The last change we need to make is in the render() method. We need to bind our instance_buffer and we need to change the range we’re using in draw_indexed() to include the number of instances.
// UPDATED! render_pass.draw_indexed(0..self.num_indices, 0, 0..self.instances.len() as _);
Make sure if you add new instances to the Vec, that you recreate the instance_buffer and as well as camera_bind_group, otherwise your new instances won’t show up correctly.
We’ll apply the model_matrix before we apply camera_uniform.view_proj. We do this because the camera_uniform.view_proj changes the coordinate system from world space to camera space. Our model_matrix is a world space transformation, so we don’t want to be in camera space when using it.
While all of our previous work has seemed to be in 2d, we’ve actually been working in 3d the entire time! That’s part of the reason why our Vertex structure has position be an array of 3 floats instead of just 2. We can’t really see the 3d-ness of our scene, because we’re viewing things head on. We’re going to change our point of view by creating a Camera.
This tutorial is more about learning to use wgpu and less about linear algebra, so I’m going to gloss over a lot of the math involved. There’s plenty of reading material online if you’re interested in what’s going on under the hood. The first thing to know is that we need cgmath = “0.18” in our Cargo.toml.
The build_view_projection_matrix is where the magic happens.
build_view_projection_matrix就是魔法发生的地方。
The view matrix moves the world to be at the position and rotation of the camera. It’s essentialy an inverse of whatever the transform matrix of the camera would be.
The proj matrix wraps the scene to give the effect of depth. Without this, objects up close would be the same size as objects far away.
The coordinate system in Wgpu is based on DirectX, and Metal’s coordinate systems. That means that in normalized device coordinates the x axis and y axis are in the range of -1.0 to +1.0, and the z axis is 0.0 to +1.0. The cgmath crate (as well as most game math crates) are built for OpenGL’s coordinate system. This matrix will scale and translate our scene from OpenGL’s coordinate sytem to WGPU’s. We’ll define it as follows.
Note: We don’t explicitly need the OPENGL_TO_WGPU_MATRIX, but models centered on (0, 0, 0) will be halfway inside the clipping area. This is only an issue if you aren’t using a camera matrix.
asyncfnnew(window: &Window) -> Self { // let diffuse_bind_group ...
let camera = Camera { // position the camera one unit up and 2 units back // +z is out of the screen eye: (0.0, 1.0, 2.0).into(), // have it look at the origin target: (0.0, 0.0, 0.0).into(), // which way is "up" up: cgmath::Vector3::unit_y(), aspect: sc_desc.width asf32 / sc_desc.height asf32, fovy: 45.0, znear: 0.1, zfar: 100.0, };
Self { // ... camera, // ... } }
Now that we have our camera, and it can make us a view projection matrix, we need somewhere to put it. We also need some way of getting it into our shaders.
Up to this point we’ve used Buffers to store our vertex and index data, and even to load our textures. We are going to use them again to create what’s known as a uniform buffer. A uniform is a blob of data that is available to every invocation of a set of shaders. We’ve technically already used uniforms for our texture and sampler. We’re going to use them again to store our view projection matrix. To start let’s create a struct to hold our uniform.
// We need this for Rust to store our data correctly for the shaders #[repr(C)] // This is so we can store this in a buffer #[derive(Debug, Copy, Clone, bytemuck::Pod, bytemuck::Zeroable)] structCameraUniform { // We can't use cgmath with bytemuck directly so we'll have // to convert the Matrix4 into a 4x4 f32 array view_proj: [[f32; 4]; 4], }
Cool, now that we have a uniform buffer, what do we do with it? The answer is we create a bind group for it. First we have to create the bind group layout.
既然我们有了一个uniform的缓冲区,我们该怎么处理它呢?答案是我们为它创建一个bind group。首先,我们必须创建bind group layout。
According to the WGSL Spec, The block decorator indicates this structure type represents the contents of a buffer resource occupying a single binding slot in the shader’s resource interface. Any structure used as a uniform must be annotated with [[block]]
Because we’ve created a new bind group, we need to specify which one we’re using in the shader. The number is determined by our render_pipeline_layout. The texture_bind_group_layout is listed first, thus it’s group(0), and camera_bind_group is second, so it’s group(1).
Multiplication order is important when it comes to matrices. The vector goes on the right, and the matrices gone on the left in order of importance.
If you run the code right now, you should get something that looks like this.
The shape’s less stretched now, but it’s still pretty static. You can experiment with moving the camera position around, but most cameras in games move around. Since this tutorial is about using wgpu and not how to process user input, I’m just going to post the CameraController code below.
fnupdate_camera(&self, camera: &mut Camera) { use cgmath::InnerSpace; let forward = camera.target - camera.eye; let forward_norm = forward.normalize(); let forward_mag = forward.magnitude();
// Prevents glitching when camera gets too close to the // center of the scene. ifself.is_forward_pressed && forward_mag > self.speed { camera.eye += forward_norm * self.speed; } ifself.is_backward_pressed { camera.eye -= forward_norm * self.speed; }
let right = forward_norm.cross(camera.up);
// Redo radius calc in case the up/ down is pressed. let forward = camera.target - camera.eye; let forward_mag = forward.magnitude();
ifself.is_right_pressed { // Rescale the distance between the target and eye so // that it doesn't change. The eye therefore still // lies on the circle made by the target and eye. camera.eye = camera.target - (forward + right * self.speed).normalize() * forward_mag; } ifself.is_left_pressed { camera.eye = camera.target - (forward - right * self.speed).normalize() * forward_mag; } } }
This code is not perfect. The camera slowly moves back when you rotate it. It works for our purposes though. Feel free to improve it!
这个代码并不完美。旋转相机时,相机会慢慢向后移动。不过,它对我们的目的是有效的。请随意改进它!
We still need to plug this into our existing code to make it do anything. Add the controller to State and create it in new().
Up to this point, the camera controller isn’t actually doing anything. The values in our uniform buffer need to be updated. There are a few main methods to do that.
We can create a separate buffer and copy it’s contents to our camera_buffer. The new buffer is known as a staging buffer. This method is usually how it’s done as it allows the contents of the main buffer (in this case camera_buffer) to only be accessible by the gpu. The gpu can do some speed optimizations which it couldn’t if we could access the buffer via the cpu.
We can call on of the mapping method’s map_read_async, and map_write_async on the buffer itself. These allow us to access a buffer’s contents directly, but requires us to deal with the async aspect of these methods this also requires our buffer to use the BufferUsage::MAP_READ and/or BufferUsage::MAP_WRITE. We won’t talk about it here, but you check out Wgpu without a window tutorial if you want to know more.
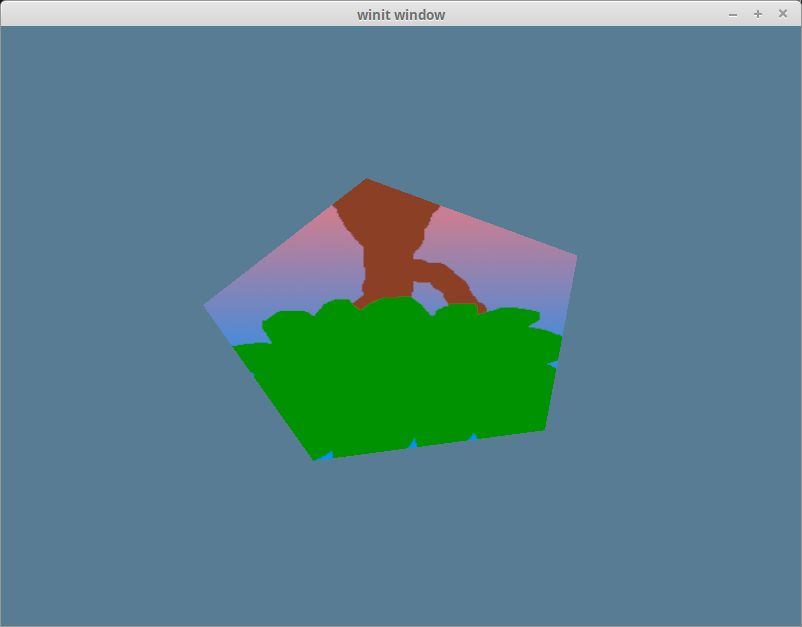
That’s all we need to do. If you run the code now you should see a pentagon with our tree texture that you can rotate around and zoom into with the wasd/arrow keys.
Up to this point we have been drawing super simple shapes. While we can make a game with just triangles, trying to draw highly detailed objects would massively limit what devices could even run our game. However, we can get around this problem with textures.
Textures are images overlayed on a triangle mesh to make it seem more detailed. There are multiple types of textures such as normal maps, bump maps, specular maps and diffuse maps. We’re going to talk about diffuse maps, or more simply, the color texture.
In State’s new() method add the following just after creating the swap_chain:
在State的new()方法中,在创建swap_chain之后添加以下内容:
1 2 3 4 5 6 7 8 9
let swap_chain = device.create_swap_chain(&surface, &sc_desc); // NEW!
let diffuse_bytes = include_bytes!("happy-tree.png"); let diffuse_image = image::load_from_memory(diffuse_bytes).unwrap(); let diffuse_rgba = diffuse_image.as_rgba8().unwrap();
use image::GenericImageView; let dimensions = diffuse_image.dimensions();
Here we grab the bytes from our image file and load them into an image which is then converted into a Vec of rgba bytes. We also save the image’s dimensions for when we create the actual Texture.
let texture_size = wgpu::Extent3d { width: dimensions.0, height: dimensions.1, depth_or_array_layers: 1, }; let diffuse_texture = device.create_texture( &wgpu::TextureDescriptor { // All textures are stored as 3D, we represent our 2D texture // by setting depth to 1. size: texture_size, mip_level_count: 1, // We'll talk about this a little later sample_count: 1, dimension: wgpu::TextureDimension::D2, // Most images are stored using sRGB so we need to reflect that here. format: wgpu::TextureFormat::Rgba8UnormSrgb, // SAMPLED tells wgpu that we want to use this texture in shaders // COPY_DST means that we want to copy data to this texture usage: wgpu::TextureUsage::SAMPLED | wgpu::TextureUsage::COPY_DST, label: Some("diffuse_texture"), } );
Getting data into a Texture
The Texture struct has no methods to interact with the data directly. However, we can use a method on the queue we created earlier called write_texture to load the texture in. Let’s take a look at how we do that:
queue.write_texture( // Tells wgpu where to copy the pixel data wgpu::ImageCopyTexture { texture: &diffuse_texture, mip_level: 0, origin: wgpu::Origin3d::ZERO, }, // The actual pixel data diffuse_rgba, // The layout of the texture wgpu::ImageDataLayout { offset: 0, bytes_per_row: std::num::NonZeroU32::new(4 * dimensions.0), rows_per_image: std::num::NonZeroU32::new(dimensions.1), }, texture_size, );
The old way of writing data to a texture was to copy the pixel data to a buffer and then copy it to the texture. Using write_texture is a bit more efficient as it uses one less buffer - I’ll leave it here though in case you need it.
The bytes_per_row field needs some consideration. This value needs to be a multiple of 256. Check out the gif tutorial for more details.
每行字节数字段需要考虑。此值必须是256的倍数。有关详细信息,请查看gif教程。
TextureViews and Samplers
Now that our texture has data in it, we need a way to use it. This is where a TextureView and a Sampler come in. A TextureView offers us a view into our texture. A Sampler controls how the Texture is sampled. Sampling works similar to the eyedropper tool in GIMP/Photoshop. Our program supplies a coordinate on the texture (known as a texture coordinate), and the sampler then returns the corresponding color based on the texture and some internal parameters.
Let’s define our diffuse_texture_view and diffuse_sampler now:
现在让我们定义diffuse_texture_view和diffuse_sampler:
1 2 3 4 5 6 7 8 9 10 11 12
// We don't need to configure the texture view much, so let's // let wgpu define it. let diffuse_texture_view = diffuse_texture.create_view(&wgpu::TextureViewDescriptor::default()); let diffuse_sampler = device.create_sampler(&wgpu::SamplerDescriptor { address_mode_u: wgpu::AddressMode::ClampToEdge, address_mode_v: wgpu::AddressMode::ClampToEdge, address_mode_w: wgpu::AddressMode::ClampToEdge, mag_filter: wgpu::FilterMode::Linear, min_filter: wgpu::FilterMode::Nearest, mipmap_filter: wgpu::FilterMode::Nearest, ..Default::default() });
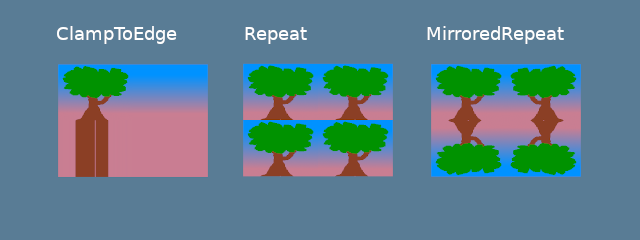
The address_mode_* parameters determine what to do if the sampler gets a texture coordinate that’s outside of the texture itself. We have a few options to choose from:
ClampToEdge: Any texture coordinates outside the texture will return the color of the nearest pixel on the edges of the texture.
Repeat: The texture will repeat as texture coordinates exceed the textures dimensions.
MirrorRepeat: Similar to Repeat, but the image will flip when going over boundaries.
ClampToEdge:纹理外部的任何纹理坐标都将返回纹理边缘上最近像素的颜色。
Repeat:纹理坐标超过纹理尺寸时,纹理将重复。
MirrorRepeat: 与“重复”类似,但图像在越过边界时将翻转。
The mag_filter and min_filter options describe what to do when a fragment covers multiple pixels, or there are multiple fragments for a single pixel. This often comes into play when viewing a surface from up close, or from far away.
Linear: Attempt to blend the in-between fragments so that they seem to flow together.
Nearest: In-between fragments will use the color of the nearest pixel. This creates an image that’s crisper from far away, but pixelated up close. This can be desirable, however, if your textures are designed to be pixelated, like in pixel art games, or voxel games like Minecraft.
Mipmaps are a complex topic, and will require their own section in the future. For now, we can say that mipmap_filter functions similar to (mag/min)_filter as it tells the sampler how to blend between mipmaps.
All these different resources are nice and all, but they don’t do us much good if we can’t plug them in anywhere. This is where BindGroups and PipelineLayouts come in.
A BindGroup describes a set of resources and how they can be accessed by a shader. We create a BindGroup using a BindGroupLayout. Let’s make one of those first.
let texture_bind_group_layout = device.create_bind_group_layout( &wgpu::BindGroupLayoutDescriptor { entries: &[ wgpu::BindGroupLayoutEntry { binding: 0, visibility: wgpu::ShaderStage::FRAGMENT, ty: wgpu::BindingType::Texture { multisampled: false, view_dimension: wgpu::TextureViewDimension::D2, sample_type: wgpu::TextureSampleType::Float { filterable: true }, }, count: None, }, wgpu::BindGroupLayoutEntry { binding: 1, visibility: wgpu::ShaderStage::FRAGMENT, ty: wgpu::BindingType::Sampler { // This is only for TextureSampleType::Depth comparison: false, // This should be true if the sample_type of the texture is: // TextureSampleType::Float { filterable: true } // Otherwise you'll get an error. filtering: true, }, count: None, }, ], label: Some("texture_bind_group_layout"), } );
Our texture_bind_group_layout has two entries: one for a sampled texture at binding 0, and one for a sampler at binding 1. Both of these bindings are visible only to the fragment shader as specified by FRAGMENT. The possible values for this field are any bitwise combination of NONE, VERTEX, FRAGMENT, or COMPUTE. Most of the time we’ll only use FRAGMENT for textures and samplers, but it’s good to know what else is available.
Looking at this you might get a bit of déjà vu! That’s because a BindGroup is a more specific declaration of the BindGroupLayout. The reason why they’re separate is it allows us to swap out BindGroups on the fly, so long as they all share the same BindGroupLayout. Each texture and sampler we create will need to be added to a BindGroup. For our purposes, we’ll create a new bind group for each texture.
Remember the PipelineLayout we created back in the pipeline section? Now we finally get to use it! The PipelineLayout contains a list of BindGroupLayouts that the pipeline can use. Modify render_pipeline_layout to use our texture_bind_group_layout.
There’s a few things we need to change about our Vertex definition. Up to now we’ve been using a color attribute to set the color of our mesh. Now that we’re using a texture, we want to replace our color with tex_coords. These coordinates will then be passed to the Sampler to retrieve the appropriate color.
With our new Vertex structure in place it’s time to update our shaders. We’ll first need to pass our tex_coords into the vertex shader and then use them over to our fragment shader to get the final color from the Sampler. Let’s start with the vertex shader:
Now that we have our vertex shader outputting our tex_coords, we need to change the fragment shader to take them in. With these coordinates, we’ll finally be able to use our sampler to get a color from our texture.
The variables t_diffuse and s_diffuse are what’s known as uniforms. We’ll go over uniforms more in the cameras section. For now, all we need to know is that group() corresponds to the 1st parameter in set_bind_group() and binding() relates to the binding specified when we created the BindGroupLayout and BindGroup.
If we run our program now we should get the following result:
That’s weird, our tree is upside down! This is because wgpu’s world coordinates have the y-axis pointing up, while texture coordinates have the y-axis pointing down. In other words, (0, 0) in texture coordinates coresponds to the top-left of the image, while (1, 1) is the bottom right.
With that in place, we now have our tree right-side up on our hexagon:
有了它,我们的树就在六边形的正确位置:
Cleaning things up
For convenience sake, let’s pull our texture code into its module. We’ll first need to add the anyhow crate to our Cargo.toml file to simplify error handling;
Note that we’re returning a CommandBuffer with our texture. This means we can load multiple textures at the same time, and then submit all their command buffers at once.
We need to import texture.rs as a module, so somewhere at the top of main.rs add the following.
我们需要将texture.rs作为一个模块导入,因此在main.rs顶部的某处添加以下内容。
1
mod texture;
The texture creation code in new() now gets a lot simpler:
1 2 3 4 5
let swap_chain = device.create_swap_chain(&surface, &sc_desc); let diffuse_bytes = include_bytes!("happy-tree.png"); // CHANGED! let diffuse_texture = texture::Texture::from_bytes(&device, &queue, diffuse_bytes, "happy-tree.png").unwrap(); // CHANGED!
// Everything up until `let texture_bind_group_layout = ...` can now be removed.
We still need to store the bind group separately so that Texture doesn’t need know how the BindGroup is laid out. Creating the diffuse_bind_group changes slightly to use the view and sampler fields of our diffuse_texture:
You were probably getting sick of me saying stuff like “we’ll get to that when we talk about buffers”. Well now’s the time to finally talk about buffers, but first…
A buffer is a blob of data on the GPU. A buffer is guaranteed to be contiguous, meaning that all the data is stored sequentially in memory. Buffers are generally used to store simple things like structs or arrays, but it can store more complex stuff such as graph structures like trees (provided all the nodes are stored together and don’t reference anything outside of the buffer). We are going to use buffers a lot, so let’s get started with two of the most important ones: the vertex buffer, and the index buffer.
Previously we’ve stored vertex data directly in the vertex shader. While that worked fine to get our bootstraps on, it simply won’t do for the long-term. The types of objects we need to draw will vary in size, and recompiling the shader whenever we need to update the model would massively slow down our program. Instead we are going to use buffers to store the vertex data we want to draw. Before we do that though we need to describe what a vertex looks like. We’ll do this by creating a new struct.
Our vertices will all have a position and a color. The position represents the x, y, and z of the vertex in 3d space. The color is the red, green, and blue values for the vertex. We need the Vertex to be copyable so we can create a buffer with it.
We arrange the vertices in counter clockwise order: top, bottom left, bottom right. We do it this way partially out of tradition, but mostly because we specified in the rasterization_state of the render_pipeline that we want the front_face of our triangle to be wgpu::FrontFace::Ccw so that we cull the back face. This means that any triangle that should be facing us should have its vertices in counter clockwise order.
To access the create_buffer_init method on wgpu::Device we’ll have to import the DeviceExt extension trait. For more information on extension traits, check out this article.
To import the extension trait, this line somewhere near the top of main.rs.
要导入扩展特性,请在main.rs顶部附近的某个位置输入如下代码。
1
use wgpu::util::DeviceExt;
You’ll note that we’re using bytemuck to cast our VERTICES as a &[u8]. The create_buffer_init() method expects a &[u8], and bytemuck::cast_slice does that for us. Add the following to your Cargo.toml.
bytemuck = { version = "1.4", features = [ "derive" ] }
We’re also going to need to implement two traits to get bytemuck to work. These are bytemuck::Pod and bytemuck::Zeroable. Pod indicates that our Vertex is “Plain Old Data”, and thus can be interpretted as a &[u8]. Zeroable indicates that we can use std::mem::zeroed(). We can modify our Vertex struct to derive these methods.
If your struct includes types that don’t implement Pod and Zeroable, you’ll need to implement these traits manually. These traits don’t require us to implement any methods, so we just need to use the following to get our code to work.
We need to tell the render_pipeline to use this buffer when we are drawing, but first we need to tell the render_pipeline how to read the buffer. We do this using VertexBufferLayouts and the vertex_buffers field that I promised we’d talk about when we created the render_pipeline.
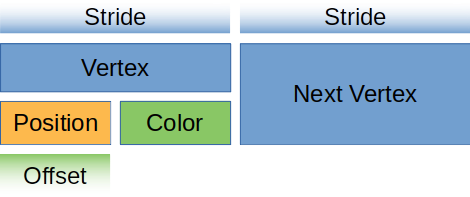
A VertexBufferLayout defines how a buffer is layed out in memory. Without this, the render_pipeline has no idea how to map the buffer in the shader. Here’s what the descriptor for a buffer full of Vertex would look like.
The array_stride defines how wide a vertex is. When the shader goes to read the next vertex, it will skip over array_stride number of bytes. In our case, array_stride will probably be 24 bytes.
step_mode tells the pipeline how often it should move to the next vertex. This seems redundant in our case, but we can specify wgpu::InputStepMode::Instance if we only want to change vertices when we start drawing a new instance. We’ll cover instancing in a later tutorial.
Vertex attributes describe the individual parts of the vertex. Generally this is a 1:1 mapping with a struct’s fields, which it is in our case.
This defines the offset in bytes that this attribute starts. The first attribute is usually zero, and any future attributes are the collective size_of the previous attributes data.
This tells the shader what location to store this attribute at. For example layout(location=0) in vec3 x in the vertex shader would correspond to the position field of the struct, while layout(location=1) in vec3 x would be the color field.
format tells the shader the shape of the attribute. Float3 corresponds to vec3 in shader code. The max value we can store in an attribute is Float4 (Uint4, and Int4 work as well). We’ll keep this in mind for when we have to store things that are bigger than Float4.
Specifying the attributes as we did now is quite verbose. We could use the vertex_attr_array macro provided by wgpu to clean things up a bit. With it our VertexBufferLayout becomes
While this is definitely nice, we would have to change the lifetime on wgpu::VertexBufferLayout to ‘static as rust wouldn’t compile the code because the result of vertex_attr_array is a temporary value, which we can’t return from a function.
set_vertex_buffer takes two parameters. The first is what buffer slot to use for this vertex buffer. You can have multiple vertex buffers set at a time.
The second parameter is the slice of the buffer to use. You can store as many objects in a buffer as your hardware allows, so slice allows us to specify which portion of the buffer to use. We use .. to specify the entire buffer.
Before we continue, we should change the render_pass.draw() call to use the number of vertices specified by VERTICES. Add a num_vertices to State, and set it to be equal to VERTICES.len().
Before our changes will have any effect, we need to update our vertex shader to get its data from the vertex buffer. We’ll also have it include the vertex color as well.
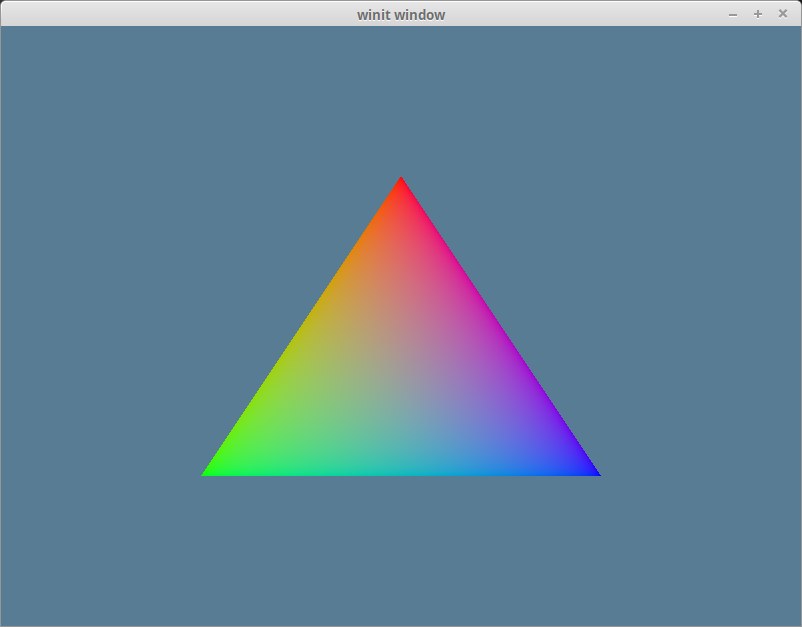
If you’ve done things correctly, you should see a triangle that looks something like this.
如果你做的正确,你应该看到一个三角形,看起来像这样。
The index buffer
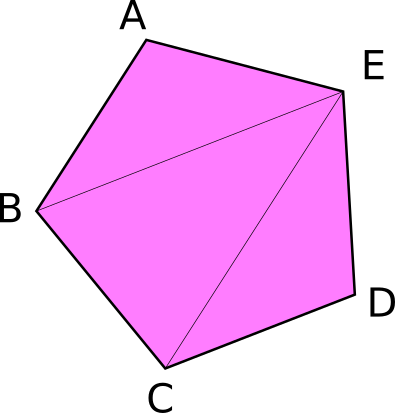
We technically don’t need an index buffer, but they still are plenty useful. An index buffer comes into play when we start using models with a lot of triangles. Consider this pentagon.
It has a total of 5 vertices, and 3 triangles. Now if we wanted to display something like this using just vertices we would need something like the following.
You’ll note though that some of the vertices are used more than once. C, and B get used twice, and E is repeated 3 times. Assuming that each float is 4 bytes, then that means of the 216 bytes we use for VERTICES, 96 of them are duplicate data. Wouldn’t it be nice if we could list these vertices once? Well we can! That’s were an index buffer comes into play.
Basically we store all the unique vertices in VERTICES and we create another buffer that stores indices to elements in VERTICES to create the triangles. Here’s an example of that with our pentagon.
Now with this setup our VERTICES take up about 120 bytes and INDICES is just 18 bytes given that u16 is 2 bytes wide. We add 2 bytes padding as wgpu requires buffers to be aligned to 4 bytes. All together our pentagon is 134 bytes in total. That means we saved 82 bytes! It may not seem like much, but when dealing with tri counts in the hundreds of thousands, indexing saves a lot of memory.
There’s a couple of things we need to change in order to use indexing. The first is we need to create a buffer to store the indices. In State’s new() method create the index_buffer after you create the vertex_buffer. Also change num_vertices to num_indices and set it equal to INDICES.len().
We don’t need to implement Pod and Zeroable for our indices, because bytemuck has already implemented them for basic types such as u16. That means we can just add index_buffer and num_indices to the State struct.
The method name is set_index_buffer not set_index_buffers. You can only have one index buffer set at a time.
When using an index buffer, you need to use draw_indexed. The draw method ignores the index buffer. Also make sure you use the number of indices (num_indices), not vertices as your model will either draw wrong, or the method will panic because there are not enough indices.
With all that you should have a garishly magenta pentagon in your window.
所有这些,你应该有一个华丽的洋红色五角大楼在你的窗口。
Color Correction
If you use a color picker on the magenta pentagon, you’ll get a hex value of #BC00BC. If you convert this to RGB values you’ll get (188, 0, 188). Dividing these values by 255 to get them into the [0, 1] range we get roughly (0.737254902, 0, 0.737254902). This is not the same as we are using for our vertex colors which is (0.5, 0.0, 0.5). The reason for this has to do with color spaces.
Most monitors use a color space know as sRGB. Our swap chain is (most likely depending on what is returned from adapter.get_swap_chain_preferred_format()) using an sRGB texture format. The sRGB format stores colors according to their relative brightness instead of their actual brightness. The reason for this is that our eyes don’t perceive light linearly. We notice more differences in darker colors than we do lighter colors.
You get an approximation of the correct color using the following formula: srgb_color = (rgb_color / 255) ^ 2.2. Doing this with an RGB value of (188, 0, 188) will give us (0.511397819, 0.0, 0.511397819). A little off from our (0.5, 0.0, 0.5). While you could tweak the formula to get the desired values, you’ll likely save a lot of time by using textures instead as they are stored as sRGB by default, so they don’t suffer from the same color inaccuracies that vertex colors do. We’ll cover textures in the next lesson.
Create a more complex shape than the one we made (aka. more than three triangles) using a vertex buffer and an index buffer. Toggle between the two with the space key.
If you’re familiar with OpenGL, you may remember using shader programs. You can think of a pipeline as a more robust version of that. A pipeline describes all the actions the gpu will perform when acting on a set of data. In this section, we will be creating a RenderPipeline specifically.
Shaders are mini programs that you send to the gpu to perform operations on your data. There are 3 main types of shader: vertex, fragment, and compute. There are others such as geometry shaders, but they’re more of an advanced topic. For now we’re just going to use vertex, and fragment shaders.
Most modern rendering uses triangles to make all shapes, from simple shapes (such as cubes), to complex ones (such as people). These triangles are stored as vertices which are the points that make up the corners of the triangles.
We use a vertex shader to manipulate the vertices, in order to transform the shape to look the way we want it.
我们使用顶点着色器来操纵顶点,以便将形状变换为我们想要的样子。
The vertices are then converted into fragments. Every pixel in the result image gets at least one fragment. Each fragment has a color that will be copied to its corresponding pixel. The fragment shader decides what color the fragment will be.
WebGPU supports two shader languages natively: SPIR-V, and WGSL. SPIR-V is actually a binary format developed by Kronos to be a compilation target for other languages such as GLSL and HLSL. It allows for easy porting of code. The only problem is that it’s not human readable as it’s a binary language. WGSL is meant to fix that. WGSL’s development focuses on getting it to easily convert into SPIR-V. WGPU even allows us to supply WGSL for our shaders.
If you’ve gone through this tutorial before you’ll likely notice that I’ve switched from using GLSL to using WGSL. Given that GLSL support is a secondary concern and that WGSL is the first class language of WGPU, I’ve elected to convert all the tutorials to use WGSL. Some of the showcase examples still use GLSL, but the main tutorial and all examples going forward will be using WGSL.
The WGSL spec and it’s inclusion in WGPU is still in development. If you run into trouble using it, you may want the folks at https://app.element.io/#/room/#wgpu:matrix.org to take a look at your code.
[[stage(vertex)]] fnmain( [[builtin(vertex_index)]] in_vertex_index: u32, ) -> VertexOutput { var out: VertexOutput; let x = f32(1 - i32(in_vertex_index)) * 0.5; let y = f32(i32(in_vertex_index & 1u) * 2 - 1) * 0.5; out.clip_position = vec4<f32>(x, y, 0.0, 1.0); return out; }
First we declare struct to store the output of our vertex shader. This consists of only one field currently which is our vertex’s clip_position. The [[builtin(position)]] bit tells WGPU that this is the value we want to use as the vertex’s clip coordinates. This is analogous to GLSL’s gl_Position variable.
Vector types such as vec4 are generic. Currently you must specify the type of value the vector will contain. Thus a 3D vector using 32bit floats would be vec3.
The next part of the shader code is the main function. We are using [[stage(vertex)]] to mark this function as a valid entry point for a vertex shader. We expect a u32 called in_vertex_index which gets its value from [[builtin(vertex_index)]].
Variables defined with var can be modified, but must specify their type. Variables created with let can have their types inferred, but their value cannot be changed during the shader.
All this does is set the color of the current fragment to brown color.
所有这些操作都是将当前片段的颜色设置为棕色。
Notice that this function is also called main. Because this function is marked as a fragment shader entry point, this is ok. You can change the names around if you like, but I’ve opted to keep them the same.
Now let’s move to the new() method, and start making the pipeline. We’ll have to load in those shaders we made earlier, as the render_pipeline requires those.
Here you can specify which function inside of the shader should be called, which is known as the entry_point. These are the functions we marked with [[stage(vertex)]] and [[stage(fragment)]]
The buffers field tells wgpu what type of vertices we want to pass to the vertex shader. We’re specifying the vertices in the vertex shader itself so we’ll leave this empty. We’ll put something there in the next tutorial.
The fragment is technically optional, so you have to wrap it in Some(). We need it if we want to store color data to the swap_chain.
The targets field tells wgpu what color outputs it should set up.Currently we only need one for the swap_chain. We use the swap_chain’s format so that copying to it is easy, and we specify that the blending should just replace old pixel data with new data. We also tell wgpu to write to all colors: red, blue, green, and alpha. We’ll talk more aboutcolor_state when we talk about textures.
primitive: wgpu::PrimitiveState { topology: wgpu::PrimitiveTopology::TriangleList, // 1. strip_index_format: None, front_face: wgpu::FrontFace::Ccw, // 2. cull_mode: Some(wgpu::Face::Back), // Setting this to anything other than Fill requires Features::NON_FILL_POLYGON_MODE polygon_mode: wgpu::PolygonMode::Fill, // Requires Features::DEPTH_CLAMPING clamp_depth: false, // Requires Features::CONSERVATIVE_RASTERIZATION conservative: false, }, // continued ...
The primitive field describes how to interpret our vertices when converting them into triangles. primitive字段描述了在将顶点转换为三角形时如何解释顶点。
Using PrimitiveTopology::TriangleList means that each three vertices will correspond to one triangle.
The front_face and cull_mode fields tell wgpu how to determine whether a given triangle is facing forward or not. FrontFace::Ccw means that a triangle is facing forward if the vertices are arranged in a counter clockwise direction. Triangles that are not considered facing forward are culled (not included in the render) as specified by CullMode::Back. We’ll cover culling a bit more when we cover Buffers.
If you run your program now, it’ll take a little longer to start, but it will still show the blue screen we got in the last section. That’s because while we created the render_pipeline, we need to modify the code in render() to actually use it.
With all that you should be seeing a lovely brown triangle. 所有这些,你应该看到一个可爱的棕色三角形。
Challenge
Create a second pipeline that uses the triangle’s position data to create a color that it then sends to the fragment shader. Have the app swap between these when you press the spacebar. Hint: you’ll need to modify VertexOutput
I’m glossing over States fields, but they’ll make more sense as I explain the code behind the methods.
我对States字段进行了润色,但当我解释方法背后的代码时,它们会更有意义。
State::new()
The code for this is pretty straight forward, but let’s break this down a bit.
这方面的代码非常简单,但是让我们把它分解一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
impl State { // ... asyncfnnew(window: &Window) -> Self { let size = window.inner_size();
// The instance is a handle to our GPU // BackendBit::PRIMARY => Vulkan + Metal + DX12 + Browser WebGPU let instance = wgpu::Instance::new(wgpu::BackendBit::PRIMARY); let surface = unsafe { instance.create_surface(window) }; let adapter = instance.request_adapter( &wgpu::RequestAdapterOptions { power_preference: wgpu::PowerPreference::default(), compatible_surface: Some(&surface), }, ).await.unwrap();
The surface is used to create the swap_chain. Our window needs to implement raw-window-handle’s HasRawWindowHandle trait to access the native window implementation for wgpu to properly create the graphics backend. Fortunately, winit’s Window fits the bill. We also need it to request our adapter.
The options I’ve passed to request_adapter aren’t guaranteed to work for all devices, but will work for most of them. If you want to get all adapters for a particular backend you can use enumerate_adapters. This will give you an iterator that you can loop over to check if one of the adapters works for your needs. 我传递给request_adapter的选项不能保证对所有设备都有效,但对大多数设备都有效。如果要获取特定后端的所有适配器,可以使用enumerate_adapters。这将为您提供一个迭代器,您可以循环检查其中一个适配器是否满足您的需要。
1 2 3 4 5 6 7 8
let adapter = instance .enumerate_adapters(wgpu::BackendBit::PRIMARY) .filter(|adapter| { // Check if this adapter supports our surface adapter.get_swap_chain_preferred_format(&surface).is_some() }) .first() .unwrap()
For more fields you can use to refine you’re search check out the docs. 有关可用于优化搜索的更多字段,请查看文档
We need the adapter to create the device and queue. 我们需要适配器来创建设备和队列。
The features field on DeviceDescriptor, allows us to specify what extra features we want. For this simple example, I’ve decided not to use any extra features. DeviceDescriptor上的features字段允许我们指定所需的额外功能。对于这个简单的例子,我决定不使用任何额外的特性。
The device you have limits the features you can use. If you want to use certain features you may need to limit what devices you support, or provide work arounds. You can get a list of features supported by your device using adapter.features(), or device.features(). You can view a full list of features here.
The limits field describes the limit of certain types of resource we can create. We’ll use the defaults for this tutorial, so we can support most devices. You can view a list of limits here.
Here we are defining and creating the swap_chain. The usage field describes how the swap_chain’s underlying textures will be used. RENDER_ATTACHMENT specifies that the textures will be used to write to the screen (we’ll talk about more TextureUsages later).
The format defines how the swap_chains textures will be stored on the gpu. Different displays prefer different formats. We use adapter.get_swap_chain_preferred_format() to figure out the best format to use.
We’ll want to call this in our main method before we enter the event loop.
在进入事件循环之前,我们希望在main方法中调用它。
1 2
// Since main can't be async, we're going to need to block letmut state = pollster::block_on(State::new(&window));
You can use heavier libraries like async_std and tokio to make main async, so you can await futures. I’ve elected not to use these crates as this tutorial is not about writing an async application, and the futures created by wgpu do not require special executor support. We just need some way to interact with wgpu’s async functions, and the pollster crate is enough for that.
If we want to support resizing in our application, we’re going to need to recreate the swap_chain everytime the window’s size changes. That’s the reason we stored the physical size and the sc_desc used to create the swapchain. With all of these, the resize method is very simple.
There’s nothing really different here from creating the swap_chain initially, so I won’t get into it.
这里与最初创建swap_chain没有什么不同,所以我就不谈了。
We call this method in main() in the event loop for the following events.
对于以下事件,我们在main函数的事件循环的中调用此方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
match event { // ...
} if window_id == window.id() => if !state.input(event) { match event { // ...
WindowEvent::Resized(physical_size) => { state.resize(*physical_size); } WindowEvent::ScaleFactorChanged { new_inner_size, .. } => { // new_inner_size is &&mut so we have to dereference it twice state.resize(**new_inner_size); } // ... }
input()
input() returns a bool to indicate whether an event has been fully processed. If the method returns true, the main loop won’t process the event any further.
We need to do a little more work in the event loop. We want State to have priority over main(). Doing that (and previous changes) should have your loop looking like this.
We don’t have anything to update yet, so leave the method empty.
1 2 3
fnupdate(&mutself) { // remove `todo!()` }
render()
Here’s where the magic happens. First we need to get a frame to render to. This will include a wgpu::Texture and wgpu::TextureView that will hold the actual image we’re drawing to (we’ll cover this more when we talk about textures).
We also need to create a CommandEncoder to create the actual commands to send to the gpu. Most modern graphics frameworks expect commands to be stored in a command buffer before being sent to the gpu. The encoder builds a command buffer that we can then send to the gpu.
Now we can actually get to clearing the screen (long time coming). We need to use the encoder to create a RenderPass. The RenderPass has all the methods to do the actual drawing. The code for creating a RenderPass is a bit nested, so I’ll copy it all here, and talk about the pieces.
// submit will accept anything that implements IntoIter self.queue.submit(std::iter::once(encoder.finish()));
Ok(()) }
First things first, let’s talk about the {}. encoder.begin_render_pass(…) borrows encoder mutably (aka &mut self). We can’t call encoder.finish() until we release that mutable borrow. The {} around encoder.begin_render_pass(…) tells rust to drop any variables within them when the code leaves that scope thus releasing the mutable borrow on encoder and allowing us to finish() it. If you don’t like the {}, you can also use drop(render_pass) to achieve the same effect.
We can get the same results by removing the {}, and the let _render_pass = line, but we need access to the _render_pass in the next tutorial, so we’ll leave it as is.
// main() event_loop.run(move |event, _, control_flow| { match event { // ... Event::RedrawRequested(_) => { state.update(); match state.render() { Ok(_) => {} // Recreate the swap_chain if lost Err(wgpu::SwapChainError::Lost) => state.resize(state.size), // The system is out of memory, we should probably quit Err(wgpu::SwapChainError::OutOfMemory) => *control_flow = ControlFlow::Exit, // All other errors (Outdated, Timeout) should be resolved by the next frame Err(e) => eprintln!("{:?}", e), } } Event::MainEventsCleared => { // RedrawRequested will only trigger once, unless we manually // request it. window.request_redraw(); } // ... } });
Wait, what’s going on with RenderPassDescriptor?
Some of you may be able to tell what’s going on just by looking at it, but I’d be remiss if I didn’t go over it. Let’s take a look at the code again.
A RenderPassDescriptor only has three fields: label, color_attachments and depth_stencil_attachment. The color_attachements describe where we are going to draw our color to. We’ll use depth_stencil_attachment later, but we’ll set it to None for now.
The RenderPassColorAttachment has the view field which informs wgpu what texture to save the colors to. In this case we specify frame.view that we created using swap_chain.get_current_frame(). This means that any colors we draw to this attachment will get drawn to the screen.
The resolve_target is the texture that will receive the resolved output. This will be the same as attachment unless multisampling is enabled. We don’t need to specify this, so we leave it as None.
The ops field takes a wpgu::Operations object. This tells wgpu what to do with the colors on the screen (specified by frame.view). The load field tells wgpu how to handle colors stored from the previous frame. Currently we are clearing the screen with a bluish color.
Once a GPUDevice has been obtained during an application initialization routine, we can describe the WebGPU platform as consisting of the following layers:
User agent implementing the specification.
Operating system with low-level native API drivers for this device.
Actual CPU and GPU hardware.
在应用程序初始化例程中获得GPU设备后,我们可以将WebGPU平台描述为由以下层组成:
实现规范的用户代理。
此设备具有低级本机API驱动的操作系统。
实际的CPU和GPU硬件。
Each layer of the WebGPU platform may have different memory types that the user agent needs to consider when implementing the specification:
The script-owned memory, such as an ArrayBuffer created by the script, is generally not accessible by a GPU driver.
A user agent may have different processes responsible for running the content and communication to the GPU driver. In this case, it uses inter-process shared memory to transfer data.
Dedicated GPUs have their own memory with high bandwidth, while integrated GPUs typically share memory with the system.
Most physical resources are allocated in the memory of type that is efficient for computation or rendering by the GPU. When the user needs to provide new data to the GPU, the data may first need to cross the process boundary in order to reach the user agent part that communicates with the GPU driver. Then it may need to be made visible to the driver, which sometimes requires a copy into driver-allocated staging memory. Finally, it may need to be transferred to the dedicated GPU memory, potentially changing the internal layout into one that is most efficient for GPUs to operate on.
All of these transitions are done by the WebGPU implementation of the user agent.
所有这些转换都由用户代理的WebGPU实现完成。
Note: This example describes the worst case, while in practice the implementation may not need to cross the process boundary, or may be able to expose the driver-managed memory directly to the user behind an ArrayBuffer, thus avoiding any data copies.