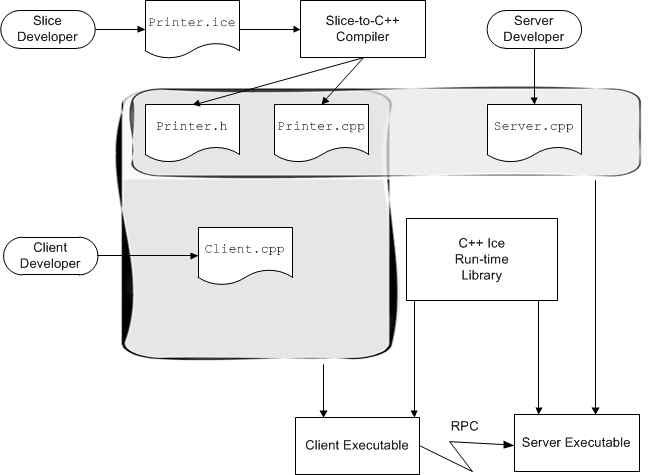
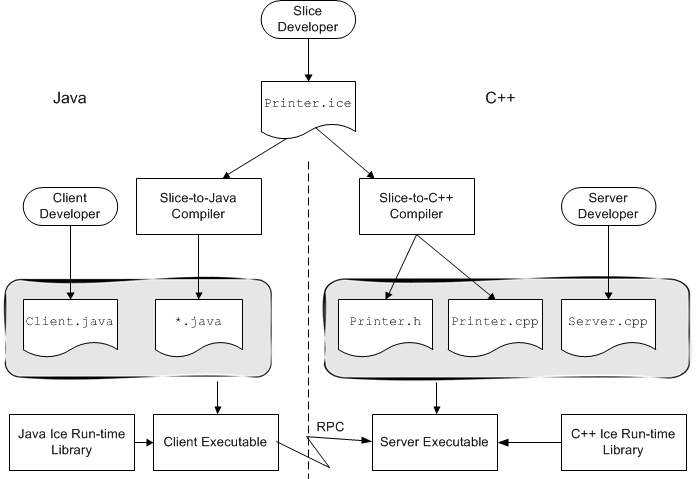
Every computing technology creates its own vocabulary as it evolves. Ice is no exception. However, the amount of new jargon used by Ice is minimal. Rather than inventing new terms, we have used existing terminology as much as possible. If you have used another middleware technology in the past, you will be familiar with much of what follows. (However, we suggest you at least skim the material because a few terms used by Ice do differ from the corresponding terms used by other middleware.)
每种计算技术都会随着其发展而创建自己的词汇表。 Ice也不例外。 然而,Ice 使用的新术语数量很少。 我们没有发明新术语,而是尽可能多地使用现有术语。 如果您过去使用过另一种中间件技术,您将会熟悉接下来的大部分内容。 (但是,我们建议您至少浏览一下材料,因为 Ice 使用的一些术语确实与其他中间件使用的相应术语不同。)
Clients and Servers
The terms client and server are not firm designations for particular parts of an application; rather, they denote roles that are taken by parts of an application for the duration of a request:
Clients are active entities. They issue requests for service to servers.
Servers are passive entities. They provide services in response to client requests.
Frequently, servers are not “pure” servers, in the sense that they never issue requests and only respond to requests. Instead, servers often act as a server on behalf of some client but, in turn, act as a client to another server in order to satisfy their client’s request.
Similarly, clients often are not “pure” clients, in the sense that they only request service from an object. Instead, clients are frequently client-server hybrids. For example, a client might start a long-running operation on a server; as part of starting the operation, the client can provide a callback object to the server that is used by the server to notify the client when the operation is complete. In that case, the client acts as a client when it starts the operation, and as a server when it is notified that the operation is complete.
Such role reversal is common in many systems, so, frequently, client-server systems could be more accurately described as peer-to-peer systems.
客户端和服务器
术语“客户端”和“服务器”并不是应用程序特定部分的固定名称。 相反,它们表示请求期间应用程序的各个部分所扮演的角色:
客户是活跃的实体。 他们向服务器发出服务请求。
服务器是被动实体。 他们根据客户的要求提供服务。
通常,服务器不是“纯”服务器,因为它们并不是从不发出请求而仅响应请求。 相反,服务器通常充当代表某个客户端的服务器,但反过来又充当另一个服务器的客户端以满足其客户端的请求。
类似地,客户端通常不是“纯粹”客户端,因为它们仅向对象请求服务。 相反,客户端通常是客户端-服务器混合体。 例如,客户端可能在服务器上启动长时间运行的操作; 作为启动操作的一部分,客户端可以向服务器提供回调对象,服务器使用该对象在操作完成时通知客户端。 在这种情况下,客户端在开始操作时充当客户端,并在收到操作完成通知时充当服务器。
这种角色反转在许多系统中很常见,因此,客户端-服务器系统通常可以更准确地描述为对等系统。
Ice Objects
An Ice object is a conceptual entity, or abstraction. An Ice object can be characterized by the following points:
An Ice object is an entity in the local or a remote address space that can respond to client requests.
A single Ice object can be instantiated in a single server or, redundantly, in multiple servers. If an object has multiple simultaneous instantiations, it is still a single Ice object.
Each Ice object has one or more interfaces. An interface is a collection of named operations that are supported by an object. Clients issue requests by invoking operations.
An operation has zero or more parameters as well as a return value. Parameters and return values have a specific type. Parameters are named and have a direction: in-parameters are initialized by the client and passed to the server; out-parameters are initialized by the server and passed to the client. (The return value is simply a special out-parameter.)
An Ice object has a distinguished interface, known as its main interface. In addition, an Ice object can provide zero or more alternate interfaces, known as facets. Clients can select among the facets of an object to choose the interface they want to work with.
Each Ice object has a unique object identity. An object’s identity is an identifying value that distinguishes the object from all other objects. The Ice object model assumes that object identities are globally unique, that is, no two objects within an Ice communication domain can have the same object identity.
In practice, you need not use object identities that are globally unique, such as UUIDs, only identities that do not clash with any other identity within your domain of interest. However, there are architectural advantages to using globally unique identifiers, which we explore in our discussion of object life cycle.
Ice对象
Ice对象是一个概念实体或抽象。 Ice对象可以具有以下几点特征:
Ice对象是本地或远程地址空间中可以响应客户端请求的实体。
单个Ice对象可以在单个服务器中实例化,或者冗余地在多个服务器中实例化。 如果一个对象有多个同时实例化,它仍然是单个Ice对象。
每个Ice对象都有一个或多个接口。 接口是对象支持的命名操作的集合。 客户端通过调用操作来发出请求。
操作具有零个或多个参数以及返回值。 参数和返回值具有特定的类型。 参数有名字并且有方向:内参数由客户端初始化并传递给服务器; 输出参数由服务器初始化并传递给客户端。 (返回值只是一个特殊的输出参数。)
Ice对象有一个独特的接口,称为主接口。 此外,Ice对象可以提供零个或多个备用接口,称为构面。客户可以在对象的各个方面进行选择,以选择他们想要使用的界面。
每个Ice对象都有一个唯一的对象标识。 对象的标识是将该对象与所有其他对象区分开来的标识值。 Ice对象模型假设对象标识是全局唯一的,即Ice通信域内的两个对象不能具有相同的对象标识。
在实践中,您不需要使用全局唯一的对象标识,例如 UUID,只需使用不与您感兴趣的域内的任何其他标识冲突的标识即可。 然而,使用全局唯一标识符具有架构优势,我们在对象生命周期的讨论中对此进行了探讨。
Proxies
For a client to be able to contact an Ice object, the client must hold a proxy for the Ice object. A proxy is an artifact that is local to the client’s address space; it represents the (possibly remote) Ice object for the client. A proxy acts as the local ambassador for an Ice object: when the client invokes an operation on the proxy, the Ice run time:
Locates the Ice object
Activates the Ice object’s server if it is not running
Activates the Ice object within the server
Transmits any in-parameters to the Ice object
Waits for the operation to complete
Returns any out-parameters and the return value to the client (or throws an exception in case of an error)
A proxy encapsulates all the necessary information for this sequence of steps to take place. In particular, a proxy contains:
Addressing information that allows the client-side run time to contact the correct server
An object identity that identifies which particular object in the server is the target of a request
An optional facet identifier that determines which particular facet of an object the proxy refers to
代理
为了使客户端能够联系Ice对象,客户端必须持有Ice对象的代理。 代理是客户端地址空间本地的工件; 它代表客户端的(可能是远程的Ice对象。 代理充当Ice对象的本地大使:当客户端调用代理上的操作时,Ice 运行时间:
找到Ice对象
如果Ice对象的服务器未运行,则激活它
激活服务器内的Ice对象
将任何内参数传输到Ice对象
等待操作完成
将任何输出参数和返回值返回给客户端(或者在出现错误时抛出异常)
代理封装了执行这一系列步骤所需的所有必要信息。 特别是,代理包含:
允许客户端运行时联系正确服务器的寻址信息
对象标识,用于标识服务器中哪个特定对象是请求的目标
可选的方面标识符,用于确定代理引用对象的哪个特定方面
Stringified Proxies
The information in a proxy can be expressed as a string. For example, the string:
SimplePrinter:default -p 10000
is a human-readable representation of a proxy. The Ice run time provides API calls that allow you to convert a proxy to its stringified form and vice versa. This is useful, for example, to store proxies in database tables or text files.
Provided that a client knows the identity of an Ice object and its addressing information, it can create a proxy “out of thin air” by supplying that information. In other words, no part of the information inside a proxy is considered opaque; a client needs to know only an object’s identity, addressing information, and (to be able to invoke an operation) the object’s type in order to contact the object.
字符串化代理
代理中的信息可以表示为字符串。 例如,字符串:
SimplePrinter:default -p 10000
是代理的人类可读表示。 Ice运行时提供API调用,允许您将代理转换为其字符串化形式,反之亦然。 例如,这对于将代理存储在数据库表或文本文件中非常有用。
如果客户端知道 Ice 对象的身份及其寻址信息,它就可以通过提供该信息“凭空”创建代理。 换句话说,代理内部的信息没有任何部分被认为是不透明的; 客户端只需要知道对象的身份、寻址信息和(能够调用操作)对象的类型即可联系该对象。
Direct Proxies
A direct proxy is a proxy that embeds an object’s identity, together with the address at which its server runs. The address is completely specified by:
a protocol identifier (such TCP/IP or UDP)
a protocol-specific address (such as a host name and port number)
To contact the object denoted by a direct proxy, the Ice run time uses the addressing information in the proxy to contact the server; the identity of the object is sent to the server with each request made by the client.
直接代理
直接代理是嵌入对象身份及其服务器运行地址的代理。 地址完全由以下方式指定:
协议标识符(例如 TCP/IP 或 UDP)
特定于协议的地址(例如主机名和端口号)
为了联系直接代理所表示的对象,Ice runtime 使用代理中的寻址信息来联系服务器; 对象的身份随着客户端发出的每个请求发送到服务器。
Indirect Proxies
An indirect proxy has two forms. It may provide only an object’s identity, or it may specify an identity together with an object adapter identifier. An object that is accessible using only its identity is called a well-known object, and the corresponding proxy is a well-known proxy. For example, the string:
SimplePrinter
is a valid proxy for a well-known object with the identity SimplePrinter.
An indirect proxy that includes an object adapter identifier has the stringified form
SimplePrinter@PrinterAdapter
Any object of the object adapter can be accessed using such a proxy, regardless of whether that object is also a well-known object.
Notice that an indirect proxy contains no addressing information. To determine the correct server, the client-side run time passes the proxy information to a location service. In turn, the location service uses the object identity or the object adapter identifier as the key in a lookup table that contains the address of the server and returns the current server address to the client. The client-side run time now knows how to contact the server and dispatches the client request as usual.
The entire process is similar to the mapping from Internet domain names to IP address by the Domain Name Service (DNS): when we use a domain name, such as www.zeroc.com, to look up a web page, the host name is first resolved to an IP address behind the scenes and, once the correct IP address is known, the IP address is used to connect to the server. With Ice, the mapping is from an object identity or object adapter identifier to a protocol-address pair, but otherwise very similar. The client-side run time knows how to contact the location service via configuration (just as web browsers know which DNS server to use via configuration).
间接代理
间接代理有两种形式。 它可以仅提供对象的标识,或者它可以与对象适配器标识符一起指定标识。 仅使用其身份即可访问的对象称为众所周知的对象,相应的代理也是众所周知的代理。 例如,字符串:
SimplePrinter
是具有标识 SimplePrinter 的知名对象的有效代理。
包含对象适配器标识符的间接代理具有字符串化形式
SimplePrinter@PrinterAdapter
对象适配器的任何对象都可以使用这样的代理来访问,无论该对象是否也是众所周知的对象。
请注意,间接代理不包含寻址信息。 为了确定正确的服务器,客户端运行时将代理信息传递给位置服务。 反过来,位置服务使用对象标识或对象适配器标识符作为包含服务器地址的查找表中的键,并将当前服务器地址返回给客户端。 客户端运行时现在知道如何联系服务器并像往常一样分派客户端请求。
整个过程类似于域名服务(DNS)从互联网域名到IP地址的映射:当我们使用域名(例如www.zeroc.com)来查找网页时,主机名是 首先在后台解析为 IP 地址,一旦知道正确的 IP 地址,就会使用该 IP 地址连接到服务器。 对于 Ice,映射是从对象标识或对象适配器标识符到协议地址对,但在其他方面非常相似。 客户端运行时知道如何通过配置联系位置服务(就像 Web 浏览器通过配置知道要使用哪个 DNS 服务器一样)。
Direct Versus Indirect Binding
The process of resolving the information in a proxy to protocol-address pair is known as binding. Not surprisingly, direct binding is used for direct proxies, and indirect binding is used for indirect proxies.
The main advantage of indirect binding is that it allows us to move servers around (that is, change their address) without invalidating existing proxies that are held by clients. In other words, direct proxies avoid the extra lookup to locate the server but no longer work if a server is moved to a different machine. On the other hand, indirect proxies continue to work even if we move (or migrate) a server.
直接绑定与间接绑定
将代理中的信息解析为协议地址对的过程称为绑定。 毫不奇怪,直接绑定用于直接代理,间接绑定用于间接代理。
间接绑定的主要优点是它允许我们移动服务器(即更改其地址),而不会使客户端持有的现有代理失效。 换句话说,直接代理避免了定位服务器的额外查找,但如果服务器移动到另一台计算机,则直接代理不再起作用。 另一方面,即使我们移动(或迁移)服务器,间接代理仍然可以继续工作。
Fixed Proxies
A fixed proxy is a proxy that is bound to a particular connection: instead of containing addressing information or an adapter name, the proxy contains a connection handle. The connection handle stays valid only for as long as the connection stays open so, once the connection is closed, the proxy no longer works (and will never work again). Fixed proxies cannot be marshaled, that is, they cannot be passed as parameters on operation invocations. Fixed proxies are used to allow bidirectional communication, so a server can make callbacks to a client without having to open a new connection.
固定代理
固定代理是绑定到特定连接的代理:代理包含连接句柄,而不是包含寻址信息或适配器名称。 连接句柄仅在连接保持打开状态时保持有效,因此,一旦连接关闭,代理就不再工作(并且永远不会再工作)。 固定代理无法封送,即它们无法作为操作调用的参数传递。 固定代理用于允许双向通信,因此服务器可以对客户端进行回调,而无需打开新连接。
Routed Proxies
A routed proxy is a proxy that forwards all invocations to a specific target object, instead of sending invocations directly to the actual target. Routed proxies are useful for implementing services such as Glacier2, which enables clients to communicate with servers that are behind a firewall.
路由代理
路由代理是将所有调用转发到特定目标对象的代理,而不是将调用直接发送到实际目标。 路由代理对于实现 Glacier2 等服务非常有用,它使客户端能够与防火墙后面的服务器进行通信。
Replication
In Ice, replication involves making object adapters (and their objects) available at multiple addresses. The goal of replication is usually to provide redundancy by running the same server on several computers. If one of the computers should happen to fail, a server still remains available on the others.
The use of replication implies that applications are designed for it. In particular, it means a client can access an object via one address and obtain the same result as from any other address. Either these objects are stateless, or their implementations are designed to synchronize with a database (or each other) in order to maintain a consistent view of each object’s state.
Ice supports a limited form of replication when a proxy specifies multiple addresses for an object. The Ice run time selects one of the addresses at random for its initial connection attempt and tries all of them in the case of a failure. For example, consider this proxy:
SimplePrinter:tcp -h server1 -p 10001:tcp -h server2 -p 10002
The proxy states that the object with identity SimplePrinter is available using TCP at two addresses, one on the host server1 and another on the host server2. The burden falls to users or system administrators to ensure that the servers are actually running on these computers at the specified ports.
复制
在 Ice 中,复制涉及使对象适配器(及其对象)在多个地址可用。 复制的目标通常是通过在多台计算机上运行同一服务器来提供冗余。 如果其中一台计算机发生故障,其他计算机上的服务器仍然可用。
复制的使用意味着应用程序是为此设计的。 具体来说,这意味着客户端可以通过一个地址访问一个对象,并获得与从任何其他地址访问相同的结果。 这些对象要么是无状态的,要么它们的实现被设计为与数据库(或彼此)同步,以便维护每个对象状态的一致视图。
当代理为对象指定多个地址时,Ice 支持有限形式的复制。 Ice run time 随机选择一个地址进行初始连接尝试,并在失败时尝试所有地址。 例如,考虑这个代理:
SimplePrinter:tcp -h server1 -p 10001:tcp -h server2 -p 10002
代理声明具有身份 SimplePrinter 的对象可通过 TCP 在两个地址上使用,一个位于主机 server1 上,另一个位于主机 server2 上。 用户或系统管理员有责任确保服务器实际上在这些计算机上的指定端口上运行。
Replica Groups
In addition to the proxy-based replication described above, Ice supports a more useful form of replication known as replica groups that requires the use of a location service.
A replica group has a unique identifier and consists of any number of object adapters. An object adapter may be a member of at most one replica group; such an adapter is considered to be a replicated object adapter.
After a replica group has been established, its identifier can be used in an indirect proxy in place of an adapter identifier. For example, a replica group identified as PrinterAdapters can be used in a proxy as shown below:
SimplePrinter@PrinterAdapters
The replica group is treated by the location service as a “virtual object adapter.” The behavior of the location service when resolving an indirect proxy containing a replica group id is an implementation detail. For example, the location service could decide to return the addresses of all object adapters in the group, in which case the client’s Ice run time would select one of the addresses at random using the limited form of replication discussed earlier. Another possibility is for the location service to return only one address, which it decided upon using some heuristic.
Regardless of the way in which a location service resolves a replica group, the key benefit is indirection: the location service as a middleman can add more intelligence to the binding process.
副本组
除了上述基于代理的复制之外,Ice还支持一种更有用的复制形式,称为副本组,它需要使用位置服务。
副本组具有唯一标识符并由任意数量的对象适配器组成。 一个对象适配器最多可以是一个副本组的成员; 这样的适配器被认为是复制对象适配器。
建立副本组后,可以在间接代理中使用其标识符来代替适配器标识符。 例如,标识为 PrinterAdapters 的副本组可以在代理中使用,如下所示:
SimplePrinter@PrinterAdapters
位置服务将副本组视为“虚拟对象适配器”。 解析包含副本组 ID 的间接代理时位置服务的行为是一个实现细节。 例如,位置服务可以决定返回组中所有对象适配器的地址,在这种情况下,客户端的 Ice run time 将使用前面讨论的有限复制形式随机选择地址之一。 另一种可能性是定位服务仅返回一个地址,这是它使用某种启发式方法决定的。
无论位置服务以何种方式解析副本组,关键的好处是间接性:位置服务作为中间人可以为绑定过程添加更多智能。
Servants
As we mentioned, an Ice Object is a conceptual entity that has a type, identity, and addressing information. However, client requests ultimately must end up with a concrete server-side processing entity that can provide the behavior for an operation invocation. To put this differently, a client request must ultimately end up executing code inside the server, with that code written in a specific programming language and executing on a specific processor.
The server-side artifact that provides behavior for operation invocations is known as a servant. A servant provides substance for (or incarnates) one or more Ice objects. In practice, a servant is simply an instance of a class that is written by the server developer and that is registered with the server-side run time as the servant for one or more Ice objects. Methods on the class correspond to the operations on the Ice object’s interface and provide the behavior for the operations.
A single servant can incarnate a single Ice object at a time or several Ice objects simultaneously. If the former, the identity of the Ice object incarnated by the servant is implicit in the servant. If the latter, the servant is provided the identity of the Ice object with each request, so it can decide which object to incarnate for the duration of the request.
Conversely, a single Ice object can have multiple servants. For example, we might choose to create a proxy for an Ice object with two different addresses for different machines. In that case, we will have two servers, with each server containing a servant for the same Ice object. When a client invokes an operation on such an Ice object, the client-side run time sends the request to exactly one server. In other words, multiple servants for a single Ice object allow you to build redundant systems: the client-side run time attempts to send the request to one server and, if that attempt fails, sends the request to the second server. An error is reported back to the client-side application code only if that second attempt also fails.
servant
正如我们提到的,Ice 对象是一个概念实体,具有类型、标识和寻址信息。 然而,客户端请求最终必须以一个具体的服务器端处理实体结束,该实体可以提供操作调用的行为。 换句话说,客户端请求最终必须在服务器内部执行代码,该代码用特定的编程语言编写并在特定的处理器上执行。
为操作调用提供行为的服务器端工件称为servant。 servant为一个或多个Ice 对象提供实例。 实际上,servant 只是由服务器开发人员编写的类的一个实例,并且在服务器端运行时注册为一个或多个 Ice 对象的servant。 类上的方法对应于 Ice 对象接口上的操作,并提供操作的行为。
单个servant可以一次化身一个 Ice 对象,也可以同时化身多个 Ice 对象。 如果是前者,servant所化身的Ice对象的身份就隐含在servant中。 如果是后者,则每次请求时都会向servant提供Ice对象的标识,因此它可以决定在请求期间具体化哪个对象。
相反,单个 Ice 对象可以有多个servant。 例如,我们可能选择为 Ice 对象创建一个代理,为不同的机器提供两个不同的地址。 在这种情况下,我们将有两个服务器,每个服务器都包含同一个 Ice 对象的servant。 当客户端调用此类 Ice 对象上的操作时,客户端运行时会将请求发送到一台服务器。 换句话说,单个 Ice 对象的多个servant 允许您构建冗余系统:客户端运行时尝试将请求发送到一台服务器,如果该尝试失败,则将请求发送到第二台服务器。 仅当第二次尝试也失败时,才会向客户端应用程序代码报告错误。
At-Most-Once Semantics
Ice requests have at-most-once semantics: the Ice run time does its best to deliver a request to the correct destination and, depending on the exact circumstances, may retry a failed request. Ice guarantees that it will either deliver the request, or, if it cannot deliver the request, inform the client with an appropriate exception; under no circumstances is a request delivered twice, that is, retries are attempted only if it is known that a previous attempt definitely failed.
One exception to this rule are datagram invocations over UDP transports. For these, duplicated UDP packets can lead to a violation of at-most-once semantics.
At-most-once semantics are important because they guarantee that operations that are not idempotent can be used safely. An idempotent operation is an operation that, if executed twice, has the same effect as if executed once. For example, x = 1; is an idempotent operation: if we execute the operation twice, the end result is the same as if we had executed it once. On the other hand, x++; is not idempotent: if we execute the operation twice, the end result is not the same as if we had executed it once.
Without at-most-once semantics, we can build distributed systems that are more robust in the presence of network failures. However, realistic systems require non-idempotent operations, so at-most-once semantics are a necessity, even though they make the system less robust in the presence of network failures. Ice permits you to mark individual operations as idempotent. For such operations, the Ice run time uses a more aggressive error recovery mechanism than for non-idempotent operations.
至多一次语义
Ice 请求具有至多一次语义:Ice 运行时会尽力将请求传递到正确的目的地,并且根据具体情况,可能会重试失败的请求。 Ice 保证它将交付请求,或者如果无法交付请求,则通知客户端并提供适当的例外; 在任何情况下,请求都不会发送两次,也就是说,只有在知道前一次尝试肯定失败的情况下才会尝试重试。
此规则的一个例外是通过 UDP 传输的数据报调用。 对于这些,重复的 UDP 数据包可能会导致违反最多一次语义。
至多一次语义很重要,因为它们保证可以安全地使用非幂等的操作。 幂等操作是指执行两次具有与执行一次相同效果的操作。 例如,x=1; 是一个幂等操作:如果我们执行该操作两次,最终结果与执行一次相同。 另一方面,x++; 不是幂等的:如果我们执行该操作两次,最终结果与执行一次不同。
没有至多一次语义,我们可以构建在出现网络故障时更加健壮的分布式系统。 然而,现实系统需要非幂等操作,因此至多一次语义是必要的,即使它们使系统在出现网络故障时变得不那么健壮。 Ice 允许您将单个操作标记为幂等。 对于此类操作,Ice run time 使用比非幂等操作更积极的错误恢复机制。
Synchronous Method Invocation
By default, the request dispatch model used by Ice is a synchronous remote procedure call: an operation invocation behaves like a local procedure call, that is, the client thread is suspended for the duration of the call and resumes when the call completes (and all its results are available).
同步方法调用
默认情况下,Ice 使用的请求调度模型是同步远程过程调用:操作调用的行为类似于本地过程调用,即客户端线程在调用期间挂起,并在调用完成时恢复(并且所有 其结果是可用的)。
Asynchronous Method Invocation
Ice also supports asynchronous method invocation (AMI): a client can invoke operations asynchronously, which means the client’s calling thread does not block while waiting for the invocation to complete. The client passes the normal parameters and, depending on the language mapping, might also pass a callback that the client-side run time invokes upon completion, or the invocation might return a future that the client can eventually use to obtain the results.
The server cannot distinguish an asynchronous invocation from a synchronous one — either way, the server simply sees that a client has invoked an operation on an object.
异步方法调用
Ice还支持异步方法调用(AMI):客户端可以异步调用操作,这意味着客户端的调用线程在等待调用完成时不会阻塞。 客户端传递普通参数,并且根据语言映射,还可能传递客户端运行时在完成时调用的回调,或者调用可能返回客户端最终可以用来获取结果的 future。
服务器无法区分异步调用和同步调用——无论哪种方式,服务器都只是看到客户端调用了对象上的操作。
Asynchronous Method Dispatch
Asynchronous method dispatch (AMD) is the server-side equivalent of AMI. For synchronous dispatch (the default), the server-side run time up-calls into the application code in the server in response to an operation invocation. While the operation is executing (or sleeping, for example, because it is waiting for data), a thread of execution is tied up in the server; that thread is released only when the operation completes.
With asynchronous method dispatch, the server-side application code is informed of the arrival of an operation invocation. However, instead of being forced to process the request immediately, the server-side application can choose to delay processing of the request and, in doing so, releases the execution thread for the request. The server-side application code is now free to do whatever it likes. Eventually, once the results of the operation are available, the server-side application code makes an API call to inform the server-side Ice run time that a request that was dispatched previously is now complete; at that point, the results of the operation are returned to the client.
Asynchronous method dispatch is useful if, for example, a server offers operations that block clients for an extended period of time. For example, the server may have an object with a get operation that returns data from an external, asynchronous data source and that blocks clients until the data becomes available. With synchronous dispatch, each client waiting for data to arrive ties up an execution thread in the server. Clearly, this approach does not scale beyond a few dozen clients. With asynchronous dispatch, hundreds or thousands of clients can be blocked in the same operation invocation without tying up any threads in the server.
Synchronous and asynchronous method dispatch are transparent to the client, that is, the client cannot tell whether a server chose to process a request synchronously or asynchronously.
异步方法分派
异步方法分派 (AMD) 是 AMI 的服务器端等效项。 对于同步调度(默认),服务器端运行时向上调用服务器中的应用程序代码以响应操作调用。 当操作正在执行时(或者休眠,例如,因为它正在等待数据),执行线程被绑定在服务器中; 仅当操作完成时该线程才会被释放。
通过异步方法分派,服务器端应用程序代码会收到操作调用到达的通知。 然而,服务器端应用程序可以选择延迟处理请求,并释放请求的执行线程,而不是被迫立即处理请求。 服务器端应用程序代码现在可以自由地执行任何操作。 最终,一旦操作结果可用,服务器端应用程序代码就会进行 API 调用,通知服务器端 Ice run time 之前分派的请求现已完成; 此时,操作结果将返回给客户端。
例如,如果服务器提供长时间阻塞客户端的操作,则异步方法分派非常有用。 例如,服务器可能有一个带有 get 操作的对象,该操作从外部异步数据源返回数据,并阻止客户端直到数据可用。 通过同步调度,每个等待数据到达的客户端都会占用服务器中的一个执行线程。 显然,这种方法的规模不能超过几十个客户。 通过异步分派,可以在同一个操作调用中阻止数百或数千个客户端,而不会占用服务器中的任何线程。
同步和异步方法分派对客户端来说是透明的,也就是说,客户端无法判断服务器选择同步还是异步处理请求。
Oneway Method Invocation
Clients can invoke an operation as a oneway operation. A oneway invocation has “best effort” semantics. For a oneway invocation, the client-side run time hands the invocation to the local transport, and the invocation completes on the client side as soon as the local transport has buffered the invocation. The actual invocation is then sent asynchronously by the operating system. The server does not reply to oneway invocations, that is, traffic flows only from client to server, but not vice versa.
Oneway invocations are unreliable. For example, the target object may not exist, in which case the invocation is simply lost. Similarly, the operation may be dispatched to a servant in the server, but the operation may fail (for example, because parameter values are invalid); if so, the client receives no notification that something has gone wrong.
Oneway invocations are possible only on operations that do not have a return value, do not have out-parameters, and do not throw user exceptions.
To the application code on the server-side, oneway invocations are transparent, that is, there is no way to distinguish a twoway invocation from a oneway invocation.
Oneway invocations are available only if the target object offers a stream-oriented transport, such as TCP/IP or SSL.
Note that, even though oneway operations are sent over a stream-oriented transport, they may be processed out of order in the server. This can happen because each invocation may be dispatched in its own thread: even though the invocations are initiated in the order in which the invocations arrive at the server, this does not mean that they will be processed in that order — the vagaries of thread scheduling can result in a oneway invocation completing before other oneway invocations that were received earlier.
单向方法调用
客户端可以将操作作为单向操作来调用。 单向调用具有“尽力而为”的语义。 对于单向调用,客户端运行时将调用交给本地传输,并且一旦本地传输缓冲了该调用,该调用就会在客户端完成。 然后,操作系统异步发送实际的调用。 服务器不回复单向调用,即流量仅从客户端流向服务器,反之则不然。
单向调用是不可靠的。 例如,目标对象可能不存在,在这种情况下,调用就会丢失。 类似地,操作可能会被调度到服务器中的servant,但操作可能会失败(例如,因为参数值无效); 如果是这样,客户端不会收到出现问题的通知。
单向调用仅适用于没有返回值、没有输出参数并且不引发用户异常的操作。
对于服务器端的应用程序代码来说,单向调用是透明的,即无法区分双向调用和单向调用。
仅当目标对象提供面向流的传输(例如 TCP/IP 或 SSL)时,单向调用才可用。
请注意,即使单向操作是通过面向流的传输发送的,它们在服务器中的处理也可能是无序的。 发生这种情况是因为每个调用都可能在其自己的线程中分派:即使调用是按照调用到达服务器的顺序启动的,但这并不意味着它们将按照该顺序进行处理 - 线程调度的变幻莫测 可能会导致单向调用先于之前收到的其他单向调用完成。
Batched Oneway Method Invocation
Each oneway invocation sends a separate message to the server. For a series of short messages, the overhead of doing so is considerable: the client- and server-side run time each must switch between user mode and kernel mode for each message and, at the networking level, each message incurs the overheads of flow-control and acknowledgement.
Batched oneway invocations allow you to send a series of oneway invocations as a single message: every time you invoke a batched oneway operation, the invocation is buffered in the client-side run time. Once you have accumulated all the oneway invocations you want to send, you make a separate API call to send all the invocations at once. The client-side run time then sends all of the buffered invocations in a single message, and the server receives all of the invocations in a single message. This avoids the overhead of repeatedly trapping into the kernel for both client and server, and is much easier on the network between them because one large message can be transmitted more efficiently than many small ones.
The individual invocations in a batched oneway message are dispatched by a single thread in the order in which they were placed into the batch. This guarantees that the individual operations in a batched oneway message are processed in order in the server.
Batched oneway invocations are particularly useful for messaging services, such as IceStorm, and for fine-grained interfaces that offer set operations for small attributes.
批量单向方法调用
每个单向调用都会向服务器发送一条单独的消息。 对于一系列短消息来说,这样做的开销是相当大的:客户端和服务器端运行时都必须为每条消息在用户模式和内核模式之间切换,并且在网络层面,每条消息都会产生流的开销 -控制和确认。
批量单向调用允许您将一系列单向调用作为单个消息发送:每次调用批量单向操作时,该调用都会在客户端运行时进行缓冲。 一旦您积累了要发送的所有单向调用,您就可以进行单独的 API 调用来一次发送所有调用。 然后,客户端运行时在单个消息中发送所有缓冲的调用,并且服务器在单个消息中接收所有调用。 这避免了客户端和服务器重复陷入内核的开销,并且在它们之间的网络上更容易,因为一条大消息可以比许多小消息更有效地传输。
批处理单向消息中的各个调用由单个线程按照它们放入批处理的顺序进行调度。 这保证了批量单向消息中的各个操作在服务器中按顺序处理。
批量单向调用对于消息服务(例如 IceStorm)以及为小属性提供设置操作的细粒度接口特别有用。
Datagram Invocations
Datagram invocations have “best effort” semantics similar to oneway invocations. However, datagram invocations require the object to offer UDP as a transport (whereas oneway invocations require TCP/IP).
Like a oneway invocation, a datagram invocation can be made only if the operation does not have a return value, out-parameters, or user exceptions. A datagram invocation uses UDP to invoke the operation. The operation returns as soon as the local UDP stack has accepted the message; the actual operation invocation is sent asynchronously by the network stack behind the scenes.
Datagrams, like oneway invocations, are unreliable: the target object may not exist in the server, the server may not be running, or the operation may be invoked in the server but fail due to invalid parameters sent by the client. As for oneway invocations, the client receives no notification of such errors.
However, unlike oneway invocations, datagram invocations have a number of additional error scenarios:
Individual invocations may simply be lost in the network.
This is due to the unreliable delivery of UDP packets. For example, if you invoke three operations in sequence, the middle invocation may be lost. (The same thing cannot happen for oneway invocations — because they are delivered over a connection-oriented transport, individual invocations cannot be lost.)
Individual invocations may arrive out of order.
Again, this is due to the nature of UDP datagrams. Because each invocation is sent as a separate datagram, and individual datagrams can take different paths through the network, it can happen that invocations arrive in an order that differs from the order in which they were sent.
Datagram invocations are well suited for small messages on LANs, where the likelihood of loss is small. They are also suited to situations in which low latency is more important than reliability, such as for fast, interactive internet applications. Finally, datagram invocations can be used to multicast messages to multiple servers simultaneously.
数据报调用
数据报调用具有与单向调用类似的“尽力而为”语义。 然而,数据报调用要求对象提供 UDP 作为传输(而单向调用则需要 TCP/IP)。
与单向调用一样,仅当操作没有返回值、输出参数或用户异常时才能进行数据报调用。 数据报调用使用 UDP 来调用操作。 一旦本地 UDP 堆栈接受了消息,操作就会返回; 实际的操作调用由幕后的网络堆栈异步发送。
数据报与单向调用一样,是不可靠的:目标对象可能不存在于服务器中,服务器可能未运行,或者操作可能在服务器中调用但由于客户端发送的无效参数而失败。 对于单向调用,客户端不会收到此类错误的通知。
然而,与单向调用不同,数据报调用有许多额外的错误场景:
单独的调用可能会在网络中丢失。
这是由于 UDP 数据包的传送不可靠造成的。 例如,如果您依次调用三个操作,则中间的调用可能会丢失。 (对于单向调用,不会发生同样的情况 - 因为它们是通过面向连接的传输传递的,单个调用不会丢失。)
个别调用可能会无序到达。
同样,这是由 UDP 数据报的性质决定的。 由于每个调用都作为单独的数据报发送,并且各个数据报可以采用不同的网络路径,因此调用到达的顺序可能与其发送的顺序不同。
数据报调用非常适合 LAN 上的小消息,因为丢失的可能性很小。 它们还适合低延迟比可靠性更重要的情况,例如快速、交互式互联网应用程序。 最后,数据报调用可用于同时将消息多播到多个服务器。
Batched Datagram Invocations
As for batched oneway invocations, batched datagram invocations allow you to accumulate a number of invocations in a buffer and then send the entire buffer as a single datagram by making an API call to flush the buffer. Batched datagrams reduce the overhead of repeated system calls and allow the underlying network to operate more efficiently. However, batched datagram invocations are useful only for batched messages whose total size does not substantially exceed the PDU limit of the network: if the size of a batched datagram gets too large, UDP fragmentation makes it more likely that one or more fragments are lost, which results in the loss of the entire batched message. However, you are guaranteed that either all invocations in a batch will be delivered, or none will be delivered. It is impossible for individual invocations within a batch to be lost.
Batched datagrams use a single thread in the server to dispatch the individual invocations in a batch. This guarantees that the invocations are made in the order in which they were queued — invocations cannot appear to be reordered in the server.
批量数据报调用
对于批量单向调用,批量数据报调用允许您在缓冲区中累积多个调用,然后通过调用 API 来刷新缓冲区,将整个缓冲区作为单个数据报发送。 批量数据报减少了重复系统调用的开销,并允许底层网络更有效地运行。 但是,批处理数据报调用仅适用于总大小未大幅超出网络 PDU 限制的批处理消息:如果批处理数据报的大小变得太大,则 UDP 碎片更有可能丢失一个或多个碎片, 这会导致整个批量消息丢失。 但是,您可以保证批次中的所有调用都将被传递,或者不会被传递。 批次内的各个调用不可能丢失。
批量数据报使用服务器中的单个线程来批量分派各个调用。 这保证了调用按照它们排队的顺序进行——调用在服务器中不会被重新排序。
Run-Time Exceptions
Any operation invocation can raise a run-time exception. Run-time exceptions are pre-defined by the Ice run time and cover common error conditions, such as connection failure, connection timeout, or resource allocation failure. Run-time exceptions are presented to the application as native exceptions and so integrate neatly with the native exception handling capabilities of languages that support exception handling.
运行时异常
任何操作调用都可能引发运行时异常。 运行时异常是由 Ice run time 预先定义的,涵盖常见的错误情况,例如连接失败、连接超时或资源分配失败。 运行时异常作为本机异常呈现给应用程序,因此与支持异常处理的语言的本机异常处理功能巧妙地集成。
User Exceptions
A server indicates application-specific error conditions by raising user exceptions to clients. User exceptions can carry an arbitrary amount of complex data and can be arranged into inheritance hierarchies, which makes it easy for clients to handle categories of errors generically, by catching an exception that is further up the inheritance hierarchy. Like run-time exceptions, user exceptions map to native exceptions.
用户异常
服务器通过向客户端引发用户异常来指示特定于应用程序的错误情况。 用户异常可以携带任意数量的复杂数据,并且可以排列成继承层次结构,这使得客户端可以通过捕获继承层次结构中更高的异常来轻松地一般处理错误类别。 与运行时异常一样,用户异常映射到本机异常。
Properties
Much of the Ice run time is configurable via properties. Properties are name-value pairs, such as Ice.Default.Protocol=tcp. Properties are typically stored in text files and parsed by the Ice run time to configure various options, such as the thread pool size, the level of tracing, and various other configuration parameters.
属性
Ice 的大部分运行时间都可以通过属性进行配置。 属性是名称-值对,例如 Ice.Default.Protocol=tcp。 属性通常存储在文本文件中,并由 Ice 运行时解析以配置各种选项,例如线程池大小、跟踪级别以及各种其他配置参数。